CBAM: Convolutional Block Attention Module
Author: Sanghyun Woo, Jongchan Park, Joon-Young Lee, In So Kweon
Date: Jul 17, 2018
URL: https://arxiv.org/abs/1807.06521
Introduction
- BAM 에서 설명한 것처럼 최근 CNN 성능 향상에 주로 연구되는 요소는 depth, width, cardinality.
- 본 논문에선 Convolutional Block Attention Module(CBAM) 제안.
- Convolution을 이용하여 channel, spatial information 을 추출하고 섞어서 사용.
- channel, spatial attention module은 각각 “what”, “where"에 대한 정보를 학습할 수 있음.
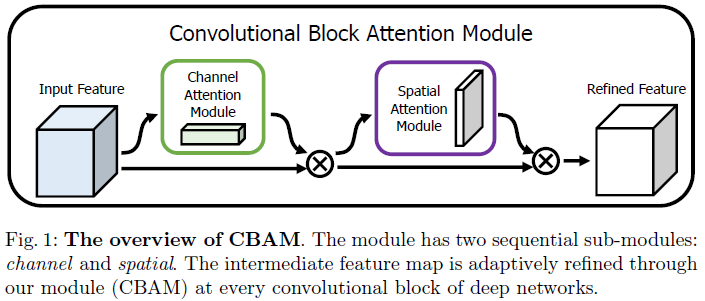
Convolutional Block Attention Module
$$F: \text{Input feature map} \\ F':\text{Channel attention module feature map} \\ F'': \text{Spatial attention module feature map} \\ F' = M_c(F)\bigotimes F \\ F'' = M_s(F')\bigotimes F'$$
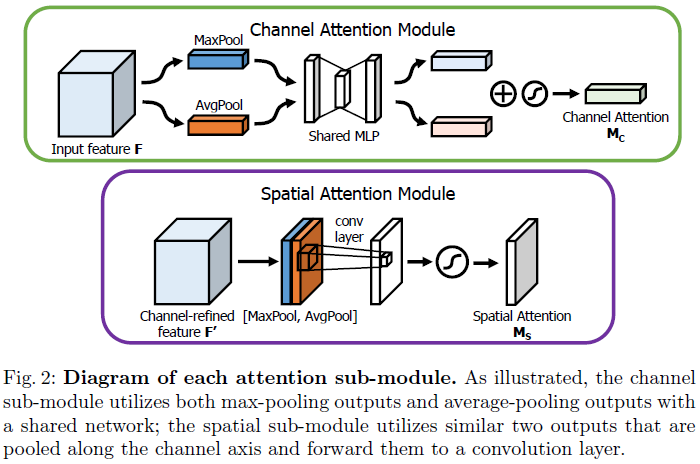
Channel attention branch
$$M_c(F) = \sigma(MLP(AvgPool(F)) + MLP(MaxPool(F))) \\ = \sigma(W1(W0(F^c_{avg})) + W1(W0(F^c_{max})))$$
W0 의 output channel 크기: F의 채널 수 / reduction ratio(r)
W1 의 output channel 크기: F의 채널 수
Spatial attention branch
$$M_s(F)=\sigma(f^{7\times7}([AvgPool(F); MaxPool(F)])) \\ = \sigma(f^{7 \times 7}([F^s_{avg};F^s_{max}]))$$
- 7x7 Convolution의 output channel 크기: 1
Arrangement of attention modules
- 두 branch의 순서를 어떻게 배열할지 고민.
- 실험적으로 Channel → Spatial 로 하기로 함.
Ablation study using ImageNet-1K
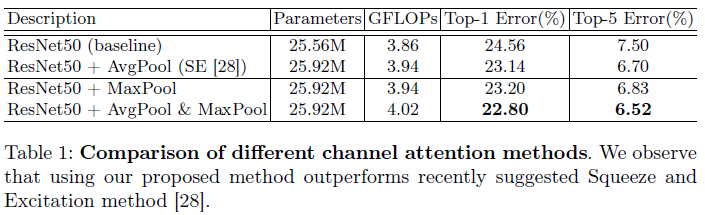
Channel attention
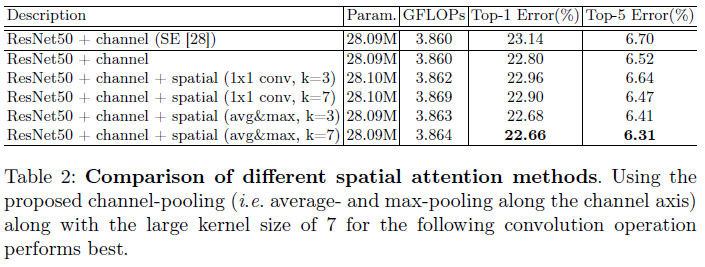
Spatial attention
- Pooling, convolution kernel size 에 따른 성능 비교
Arrangement of the channel and spatial attention
- Attention module 순서에 따른 성능 비교
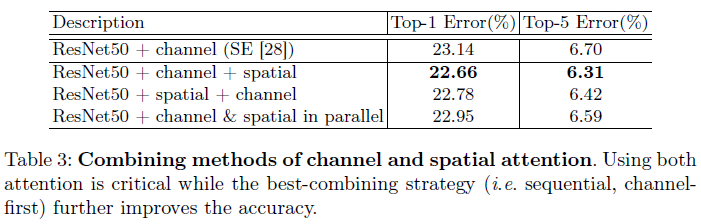
Result
Classification Result on ImageNet-1K
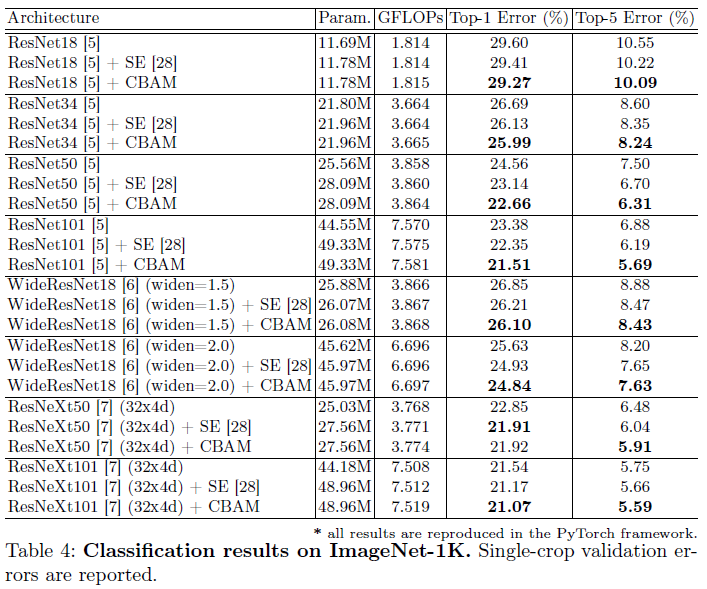
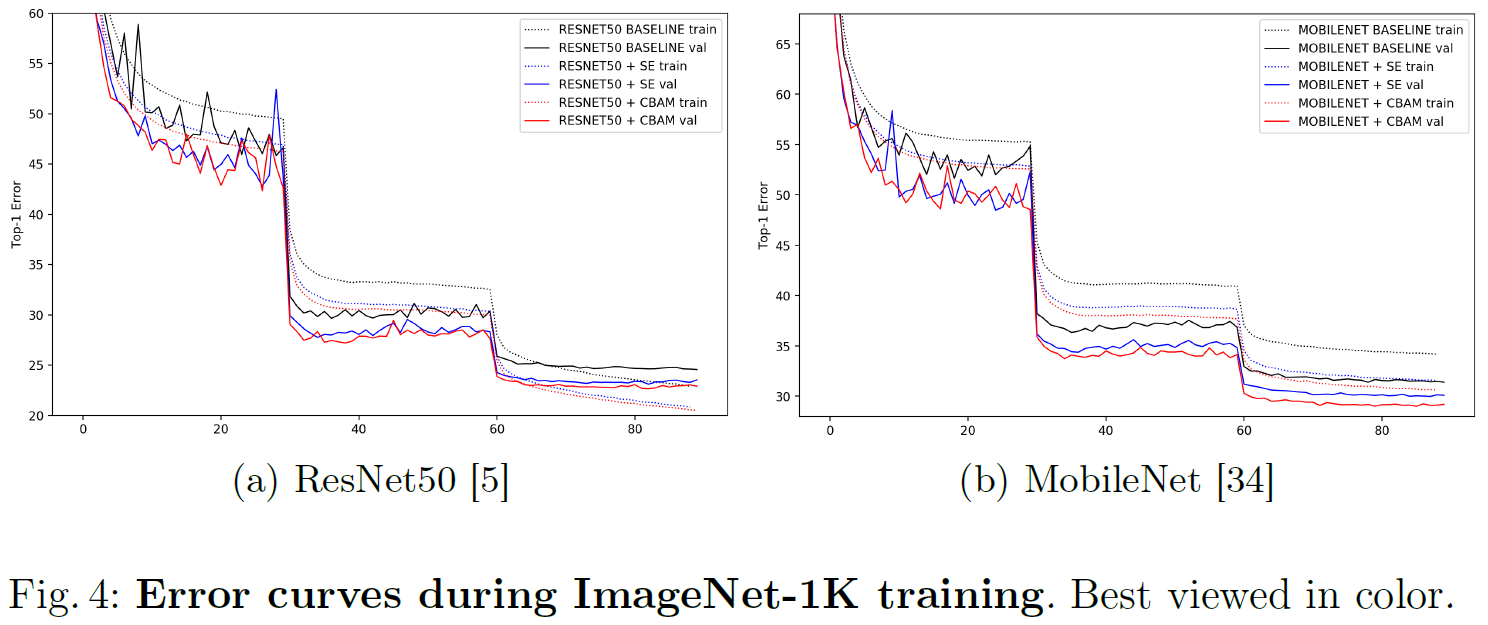
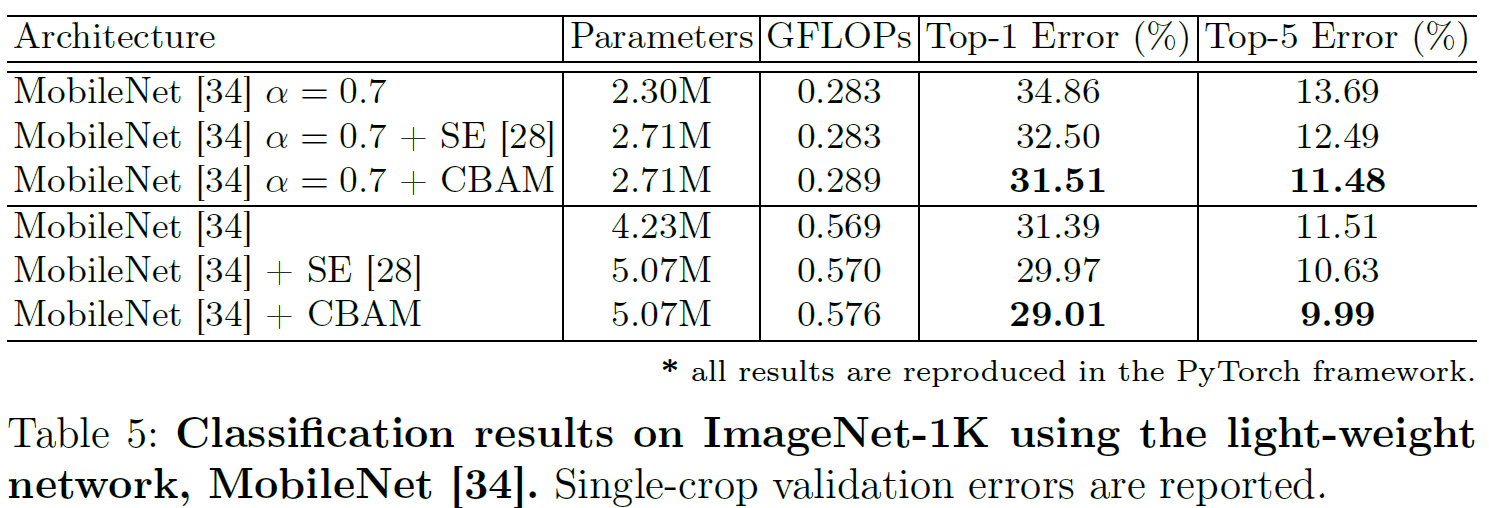
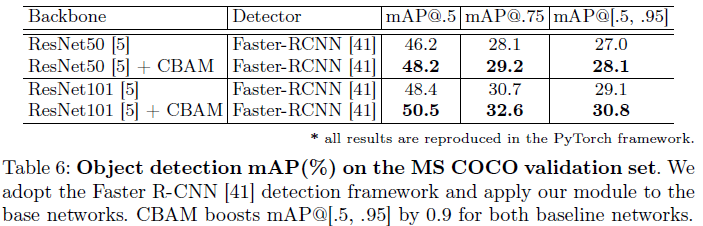
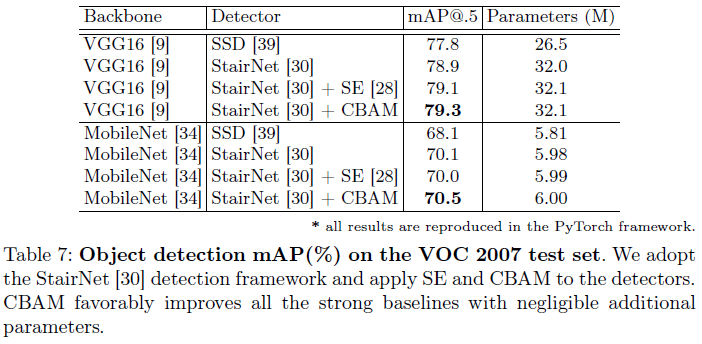
Object Detection on MS COCO and VOC 2007
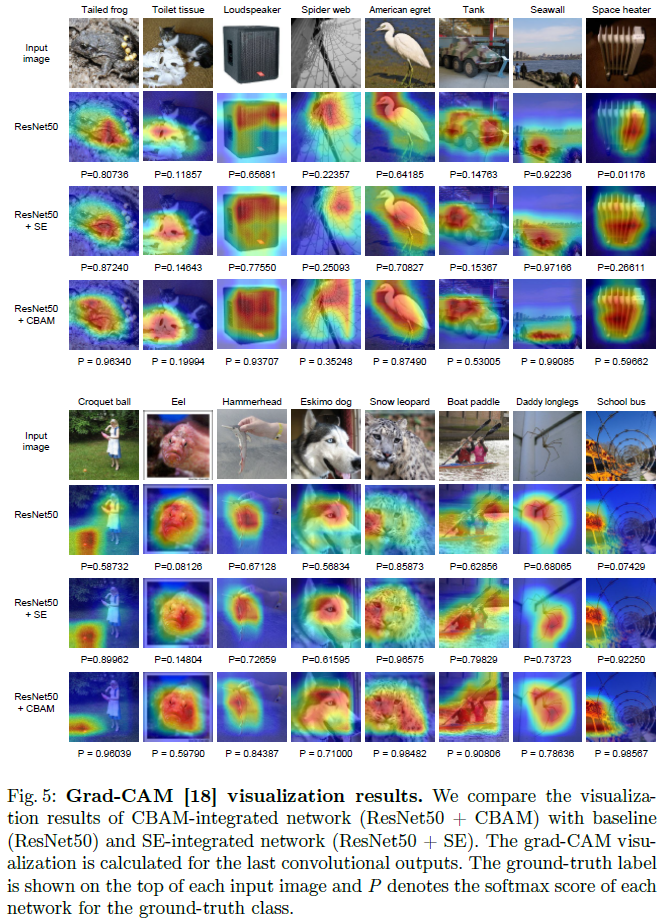
Network Visualization with Grad-CAM
P.S
- BAM과 동일하게 Original Code가 있지만….논문과 다른 부분이 매우 많음.

