Author: Andrew G. Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan,
Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam
Date: May 06, 2019
URL: https://arxiv.org/abs/1905.02244
Introduction
Efficient neural network 는 low latency, higher accuracy 와 더불어 전력소모가 줄어들게 하기 때문에 배터리 수명 보존에도 기여.
이에 힘입어 다음 세대의 더 효율적인 네트워크 제안.
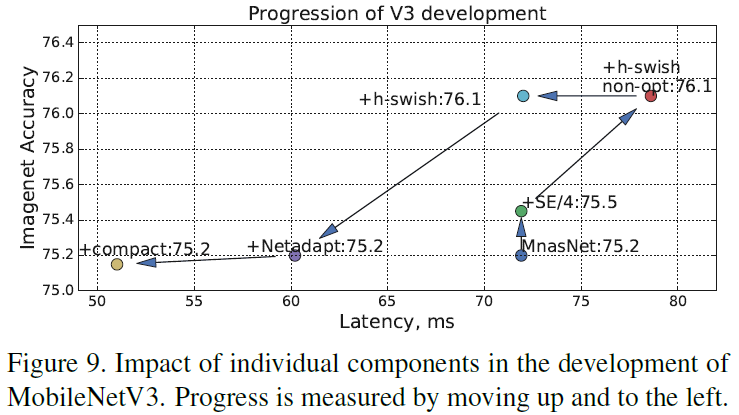
본 논문에서 중요한 것은 네 가지.
Complementary search techniques
New efficient versions of non-linearities practical
RNN-based controller, factorized hierarchical search space
NetAdapt for Layer-wise Search
platform-aware NAS로 찾은 Seed network architecture 로 시작.
매 스텝마다:
(a) 이전의 proposal 에 비해 latency가 최소 a만큼 감소된 새로운 proposal 생성.
(b) 각 proposal은 이전 스텝의 pre-trained model을 사용하여 새로 제안된 architecture를 채우고 누락된 weight에 대해선 적절한 값으로 채움. 각 proposal 은 T step 동안 finetuning하고 대략적인 accuracy 추출.
(c) 몇몇 metric을 이용하여 최적의 proposal 을 선택.