Author: Jongchan Park, Sanghyun Woo, Joon-Young Lee, In So Kweon
Date: Jul 17, 2018
URL: https://arxiv.org/abs/1807.06514
DL은 Classification, Detection, Segmentation 등 많은 패턴 인식 분야에서 강력한 Tool로 사용.
성능을 올리기 위해서 좋은 backbone을 설계하는 것이 기본적인 접근법.
직관적인 방법은 더 깊게 설계하는 것.
VGGNet는 AlexNet 보다 두배 이상.
ResNet 은 VGGNet보다 22배 이상이면서 residual connections 사용하여 gradient flow 를 향상.
GoogLeNet 은 매우 깊고 같은 layer에서 다양한 feature를 사용하여 성능 향상.
DenseNet 이전 layer의 feature map 들을 concatenation 하여 사용.
WideResNet, PyramidNet layer의 channels 를 증가하여 성능 향상.
ResNeXt, Xception과 같은 backbone은 grouped convolutions을 이용하여 성능 향상.
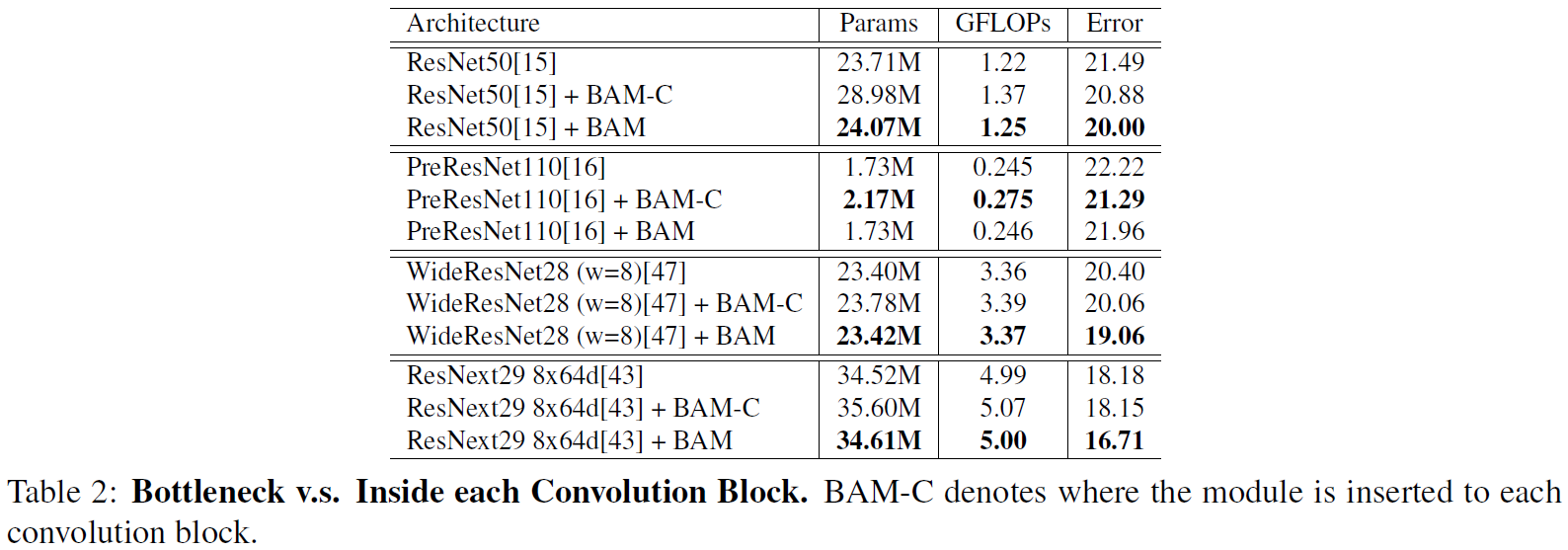
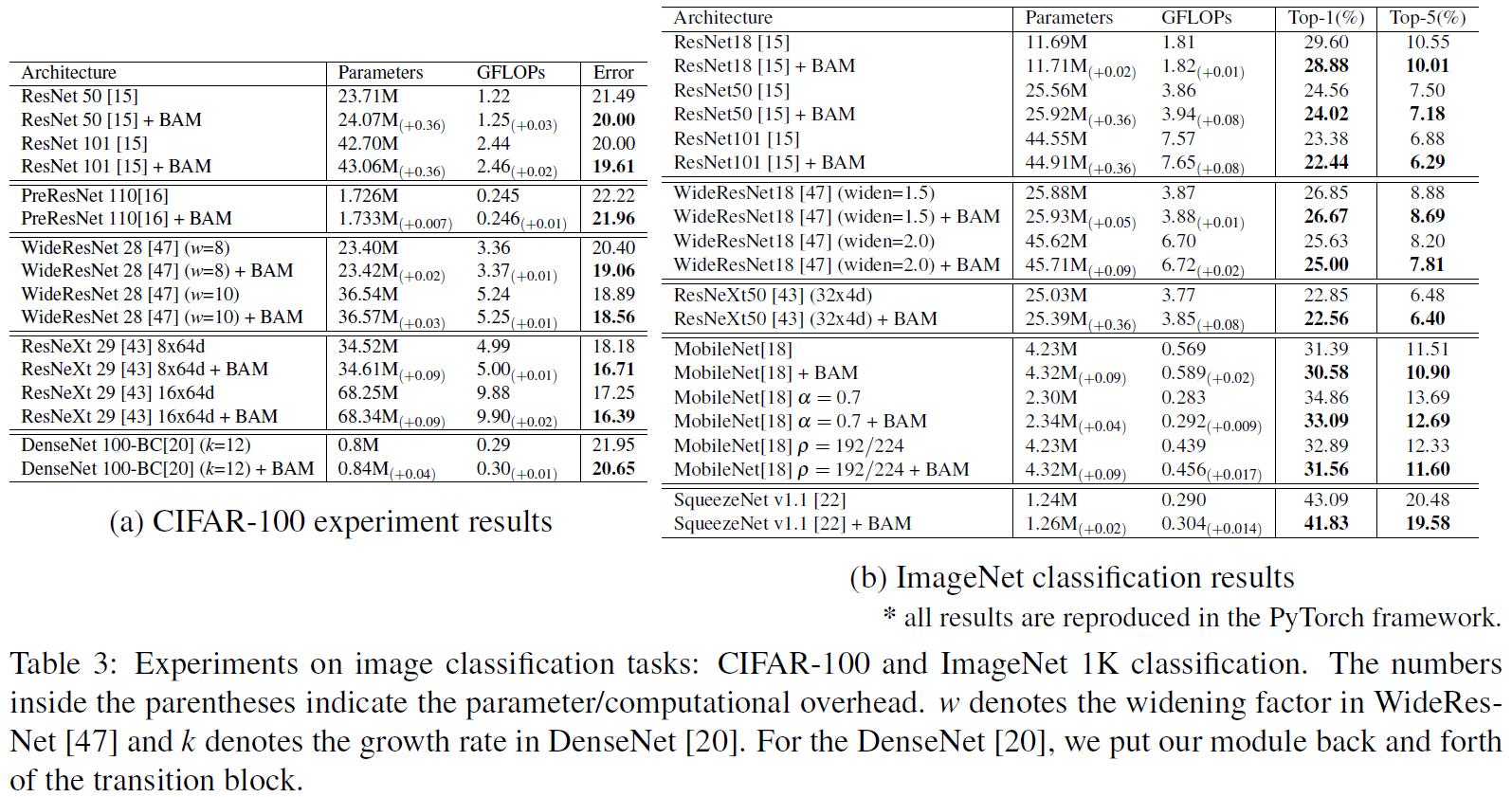
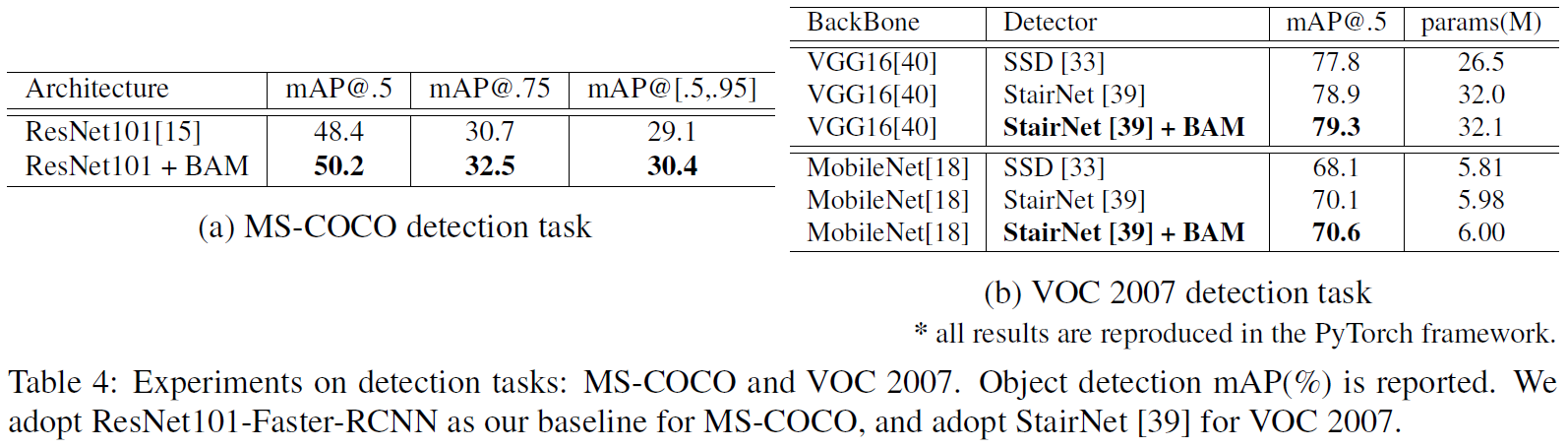
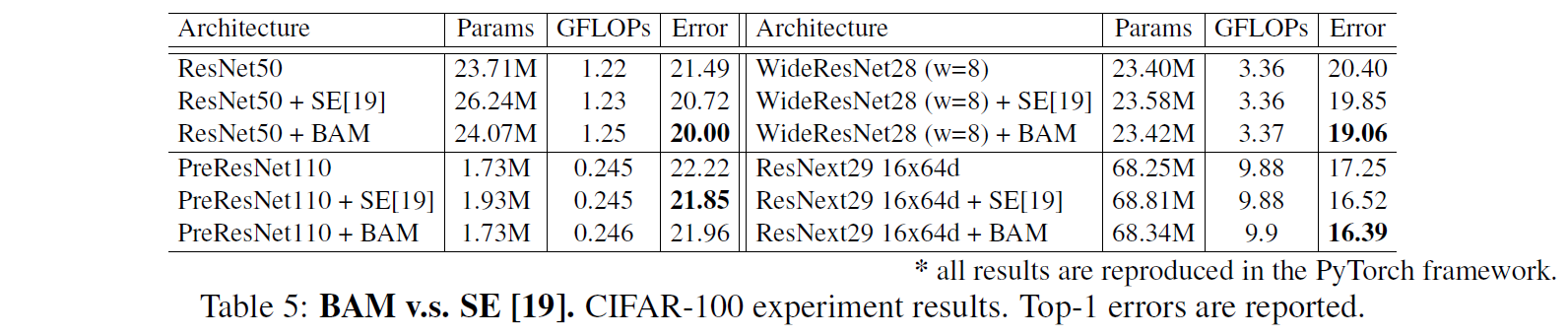
본 논문에선 attention 의 효과를 보기 위해 기존의 architecture 에 사용하기 쉬운 가벼운 Bottle Attention Module(BAM) 제안

$$F: \text{Input feature map} \\ M(F): \text{Attention map} \\ F' = F + F\bigotimes M(F) \\ M(F) = \sigma(M_c(F) + M_s(F))$$
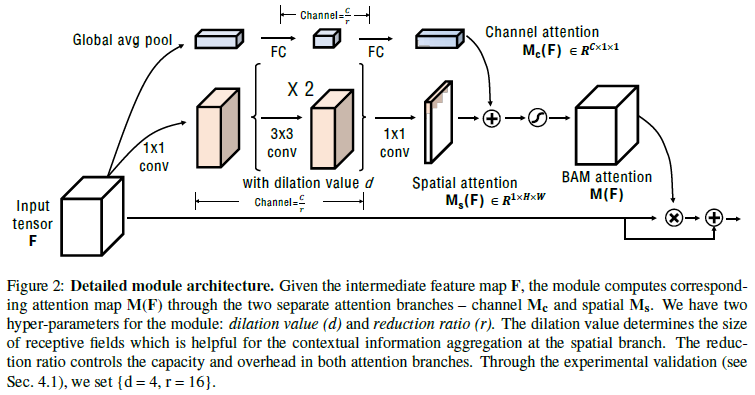
$$M_c(F) = BN(MLP(AvgPool(F))) \\ = BN(W_1(W_0AvgPool(F) + b_0)+b_1)$$
W0 의 output channel 크기: F의 채널 수 / reduction ratio(r)
W1 의 output channel 크기: F의 채널 수
$$M_s(F)=BN(f_3^{1\times1}(f_2^{3\times3}(f_1^{3\times3}(f_0^{1\times1}(F)))))$$
$$M(F) = \sigma(M_c(F) + M_s(F))$$