Author: Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko
Date: May 27, 2020
URL: https://ai.facebook.com/research/publications/end-to-end-object-detection-with-transformers
Introduction
- 현재 Object detection model들은 Input부터 Output (bounding bos, category label) 까지 Direct 하지 못함. Post processing 이 영향을 끼치기 때문에…
- 본 논문에선 Direct prediction approach 제안.
- 이전에도 몇몇 실험이 있었으나 그 당시에는 prior knowledge를 준다거나 성능이 별로 좋지 못했음.
- Transformer 를 사용.
- 새로운 Loss function 도입.
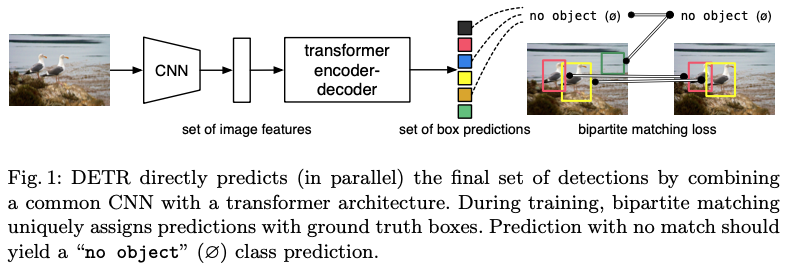
Set Prediction
- 현재까지 Direct로 set(box, class)을 prediction 하는 방법이 없음.
- Post processing 이 없는 model 제안.
- 이를 위해 Hungarian algorithm 기반의 loss 설계.
- 다른 RNN 계열보다 Long sequence 에 적합한 model
- auto-regressive model
Object detection
Set-based loss
- 기존에 bipatite matching loss 를 사용했지만 NMS 를 사용해야 성능이 향상되었음.
- 그 후 Learnable NMS 를 사용한 방법이 제시 되었으나 hand-crafted context feature 를 사용 하기에 효율적이지 못함.
Recurrent detectors
- 이름에서 알 수 있듯 RNN 계열을 도입한 Object detection
- 기존 방법에선 Small dataset을 이용했고 RNN 계열을 이용했기에 parallel 구조를 가져가지 못했음.
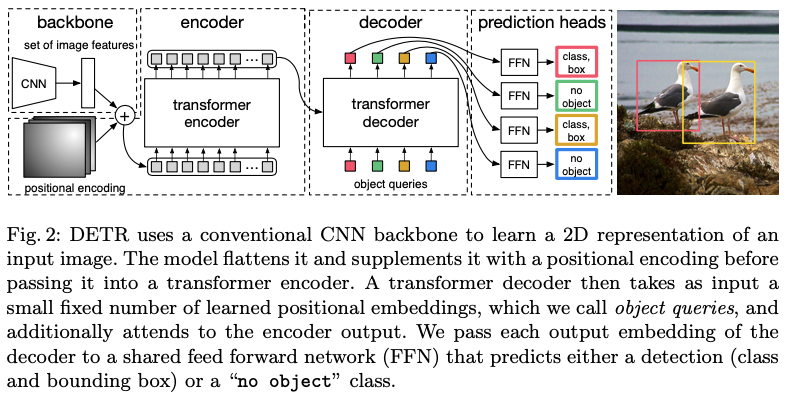
The DETR model
- DETR은 크게 두 개의 장점이 있음. → a set prediction loss, a architecture
Object detection set prediction loss
$$\hat{\sigma} = {argmin}_{\sigma \in \mathfrak{S}_N} \sum^N_i \mathcal{L}_{match}(y_i, \hat{y}_{\sigma(i)})$$
$$\mathcal{L}_{match}(y_i, \hat{y}_{\sigma(i)}) = -1_{c_i \neq \phi}\hat{p}_{\sigma(i)}(c_i) +1_{c_i \neq \phi}\mathcal{L}_{box}(b_i, \hat{b}_{\sigma(i)})$$
$$\mathcal{L}_{Hungarian}(y, \hat{y}) = \sum^N_i[-\log\hat{p}_{\hat{\sigma}(i)}(c_i) +1_{c_i \neq \phi}\mathcal{L}_{box}(b_i, \hat{b}_{\hat{\sigma}(i)})]$$
Bounding box loss
$$\lambda_{iou}\mathcal{L}_{iou}(b_i, \hat{b}_{\sigma(i)}) + \lambda_{\mathrm{L}1}|b_i - \hat{b}_{\sigma(i)}|_1$$
DETR architecture
Backbone
- 일반적인 Backbone 사용.
- 마지막 feataure map은 원본 사이즈 H, W 에 비해 32분의 1 downsampling, C는 2048
- Attention is all you need의 Transformer의 encoder와 동일한 구조.
- Fixed positional encodings 으로 인하여 permutation-invariant 한 구조!
- Attention is all you need의 Transformer의 decoder와 동일한 구조.
- 기존 Transformer와 차이는
Prediction feed-forward networks (FFNs)
- ReLU를 사용하는 d dimension의 linear layer 3 개 사용.
- 한 branch 에서는 Normalized center coordinate, height, width 를 예측.
- 다른 하나의 branch는 class label을 softmax를 이용하여 예측.
- DETR은 항상 N개의 box에 대해 예측. 하지만 실제 object 수가 적을때는 나머지 box들을 no object 로 처리.
Auxiliary decoding losses
- Transformer decoder에 Auxiliary loss 를 추가.
Experiment
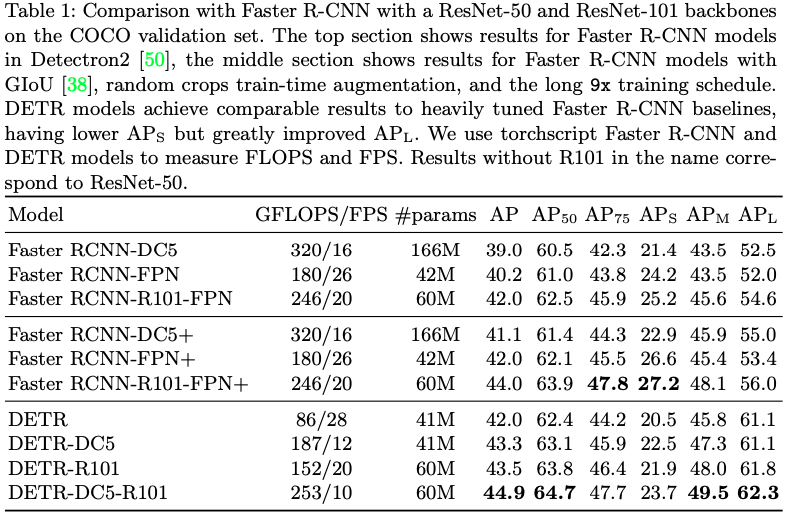
Comparison with Faster R-CNN
Ablations


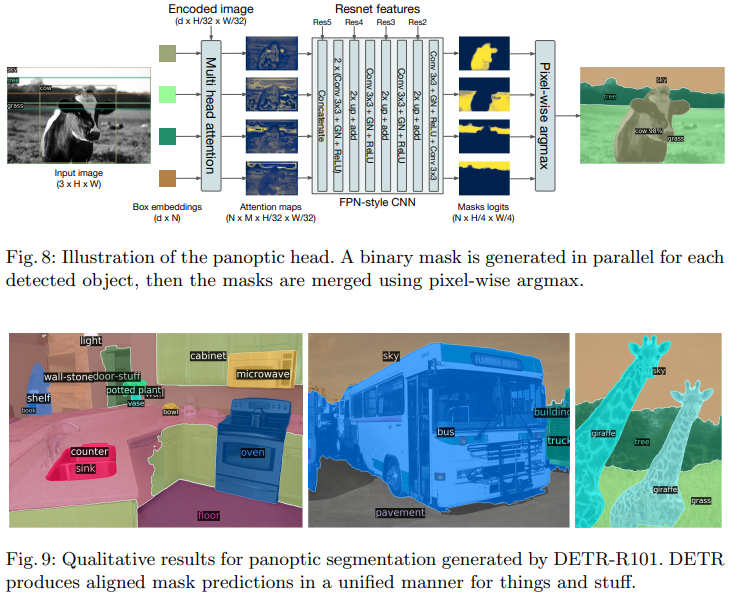
Panoptic segmentation
P.S

