근래에 많이 사용되는 depthwise separable convoltuion에서 연산량의 대부분은 pointwise convolution 이 차지.
1x1 convolution 이 차지하는 연산량은 다음과 같음.
$$h, w: \text{the spatial size of the input feature map} $$
$$c_1, c_2: \text{Number of channels about input and output }$$
$$B=hwc_1c_2, \text{ FLOPs of the }1 \times 1 \text{ convolution}$$
현 상황에서 MAC의 수식은 다음과 같음.
$$MAC = hw(c_1+c_2) +c_1c_2 = hwc_1 + hwc_2 + c_1c_2$$
$$hwc_1: \text{Number of input feature map’s element}$$
$$hwc_2: \text{Number of output feature map’s element}$$
$$c_1c_2: \text{Number of filter’s element}$$
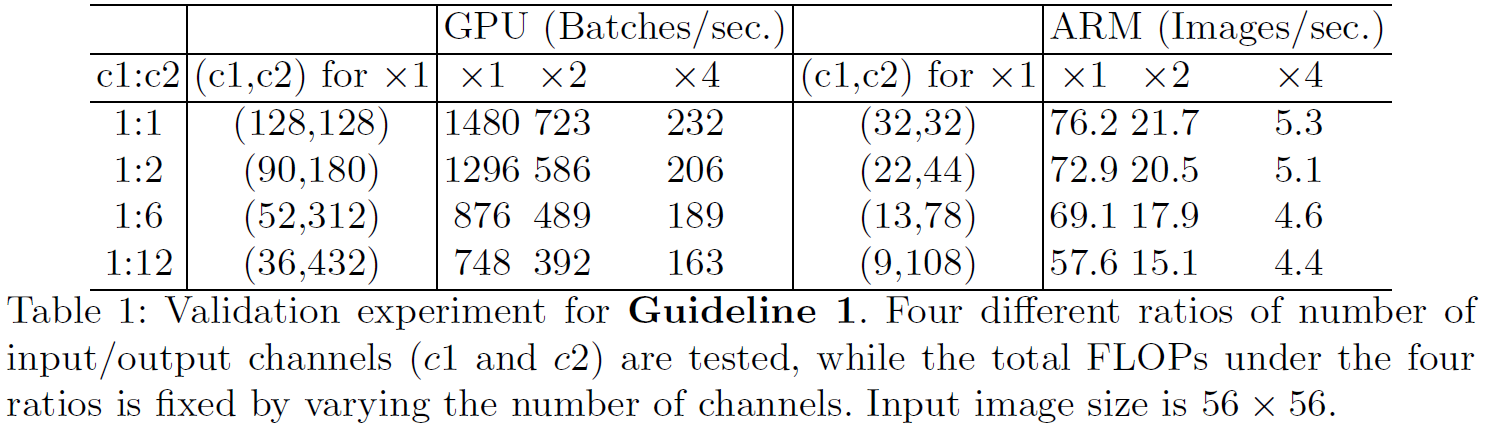
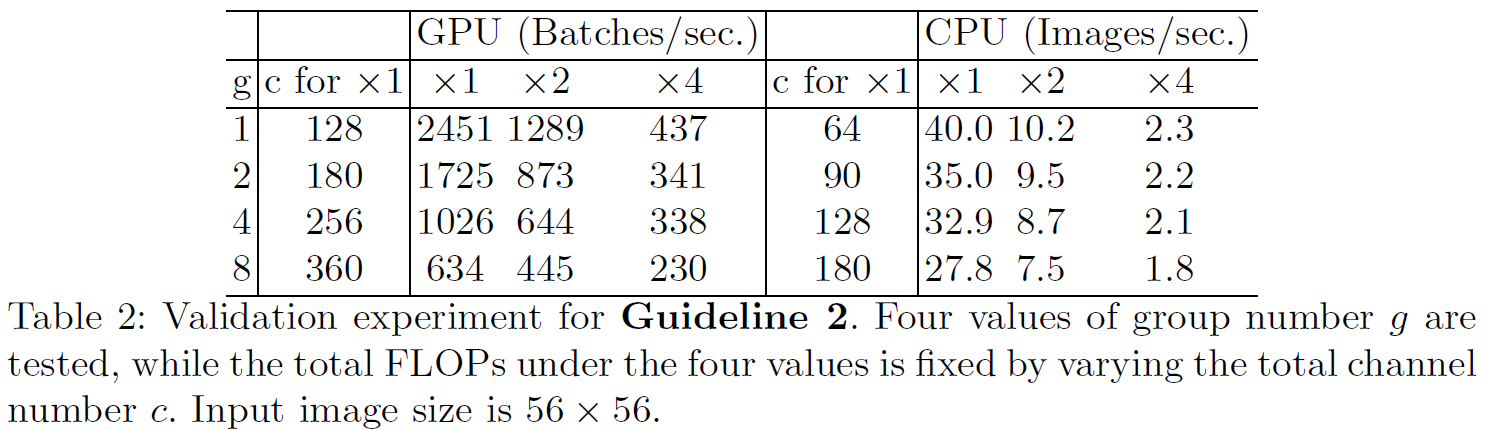
The group number should be carefully chosen based on the target platform and task. It is unwise to use a large group number simply because this may enable using more channels, because the benet of accuracy increase can easily be outweighed by the rapidly increasing computational cost.
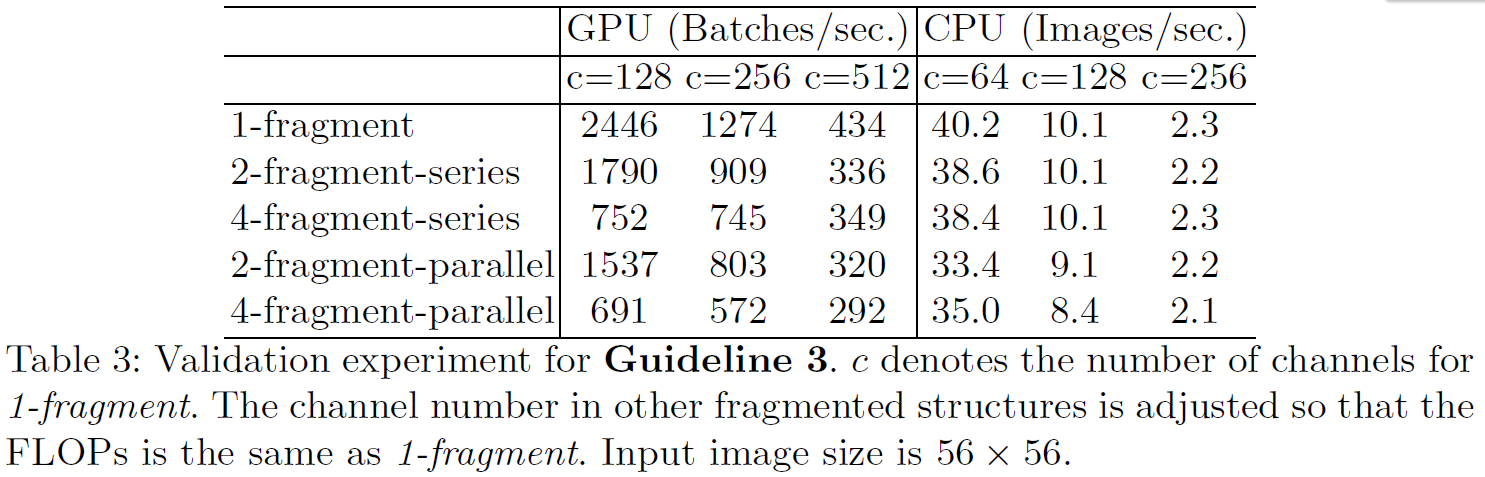
G3) Network fragmentation reduces degree of parallelism
Inception 과 같이 여러 branch를 parallel하게 구성할 경우 성능은 좋아졌지만 효율성은 감소시킴. → GPU 같은 자원에는 어울리지 않음.
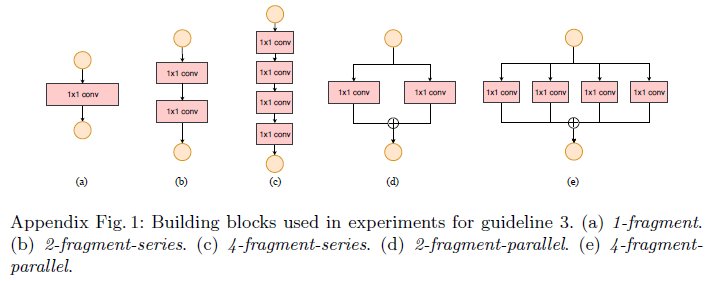
Fragmentation 에 따른 runtime 비교.
Fragmented structure has been shown benecial for accuracy, it could decrease eciency because it is unfriendly for devices with strong parallel computing powers like GPU. It also introduces extra overheads such as kernel launching and synchronization.
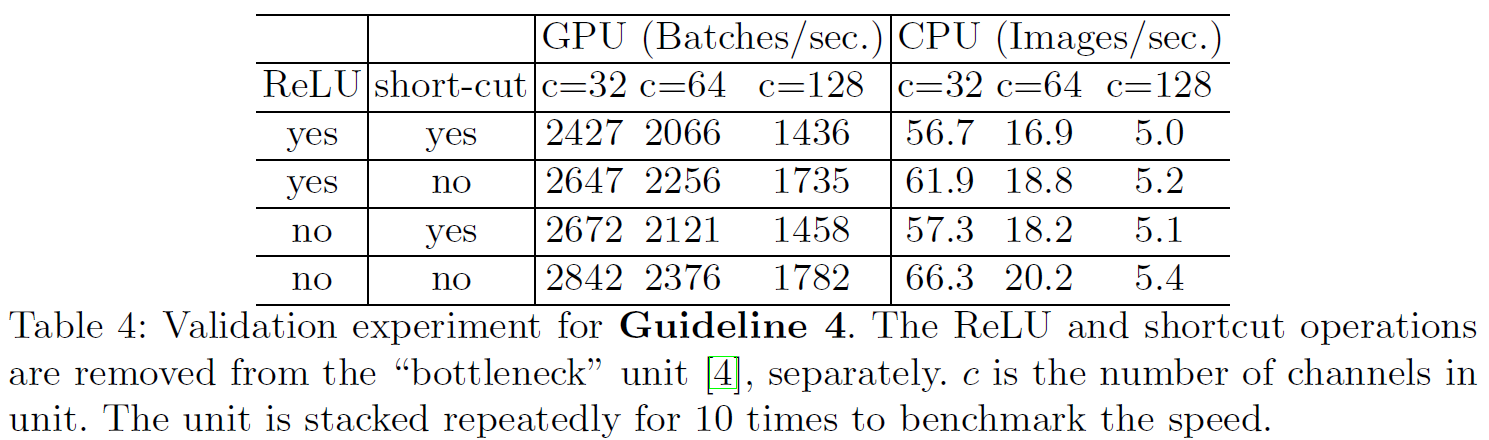
G4) Element-wise operations are non-negligible
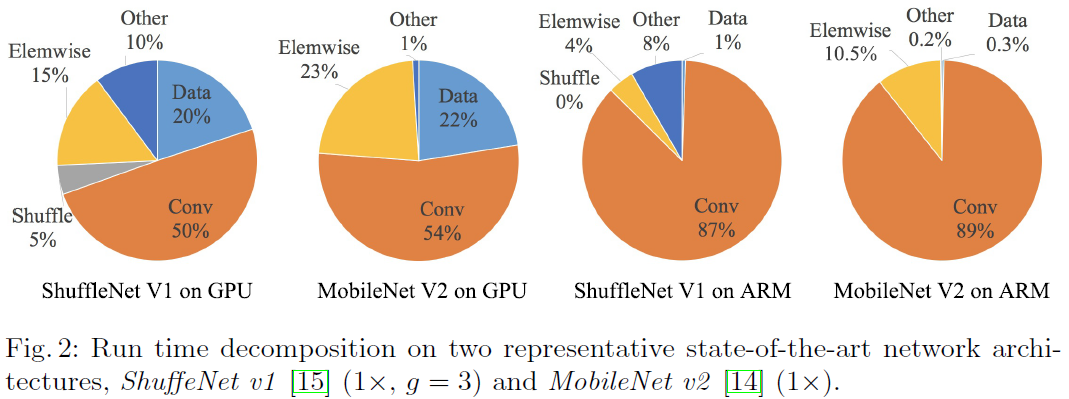
Activation, Add 와 같은 Element-wise operation들의 비율이 꽤 존재. Figure 2 참고
이 연산은 FLOPs는 적지만 상대적으로 MAC은 큼.
Depthwise convolution 또한 element-wise 여서 MAC/FLOPs 가 클 것이라 생각.
각 상황에 대한 runtime 비교.
We observe around 20% speedup is obtained on both GPU and ARM, after ReLU and shortcut are removed.
Conclusion and Discussions
use “balanced convolutions (equal channel width);
be aware of the cost of using group convolution;
reduce the degree of fragmentation;
reduce element-wise operations.
다른 네트워크들에 대한 고찰
ShuffleNet V1
Heavily group convolutions → G2
Bottleneck-like building blocks → G1
Residual Block → G3
Element-wise operation→ G4
MobileNet V2
Inverted bottleneck structure → G1
Depthwise convolution & ReLU
Element-wise operation → G4
NAS
Highly fragmentation → G3
ShueNet V2: an Ecient Architecture
Review of ShueNet v1
G1, G2, G3, G4 모두 지키지 않음.
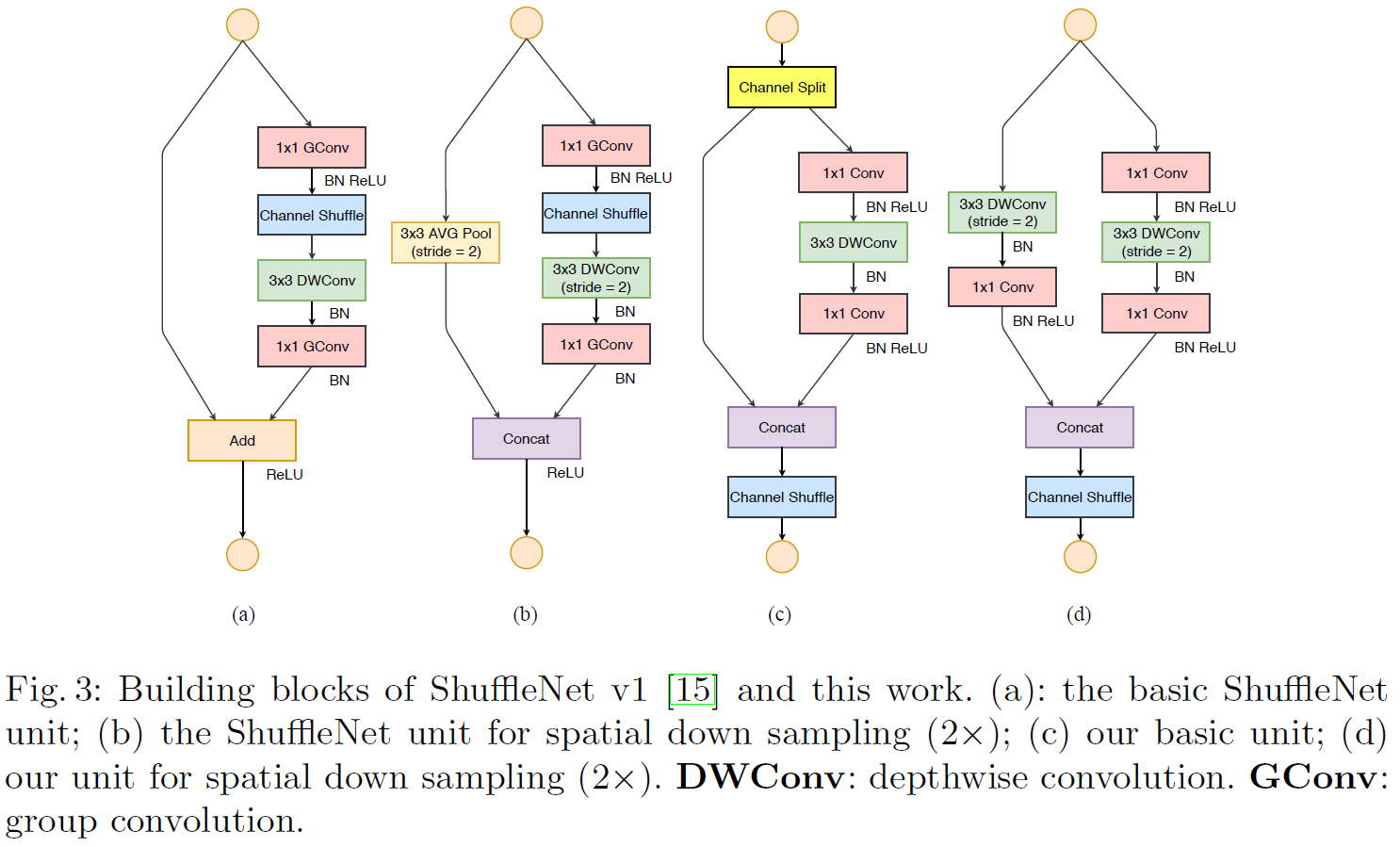
이를 해결한 구조가 ShuffleNet V2 의 유닛 (Fig 3 (c), Fig 3 (d))
Channel Split and ShueNet V2
Fig 3 (c)
Input feature 을 절반으로 나눠 두개의 branch 생성.
Left branch는 아무 연산도 진행 X. → G3 에 대한 회피법.
Right branch는 동일한 Number of filter로 1x1 Conv → 3x3 DWConv → 1x1 Conv 수행. → G1에 대한 회피법.
1x1 Conv 는 Group 을 나누지 않음 → G2에 대한 회피법.
Residual Block의 Add operation 을 Concatenate 로 변경 → G4에 대한 회피법.
Fig 3 (d)
Downsampling block
Input feature 그대로 두개의 branch 생성.
Number of filter는 모두 동일
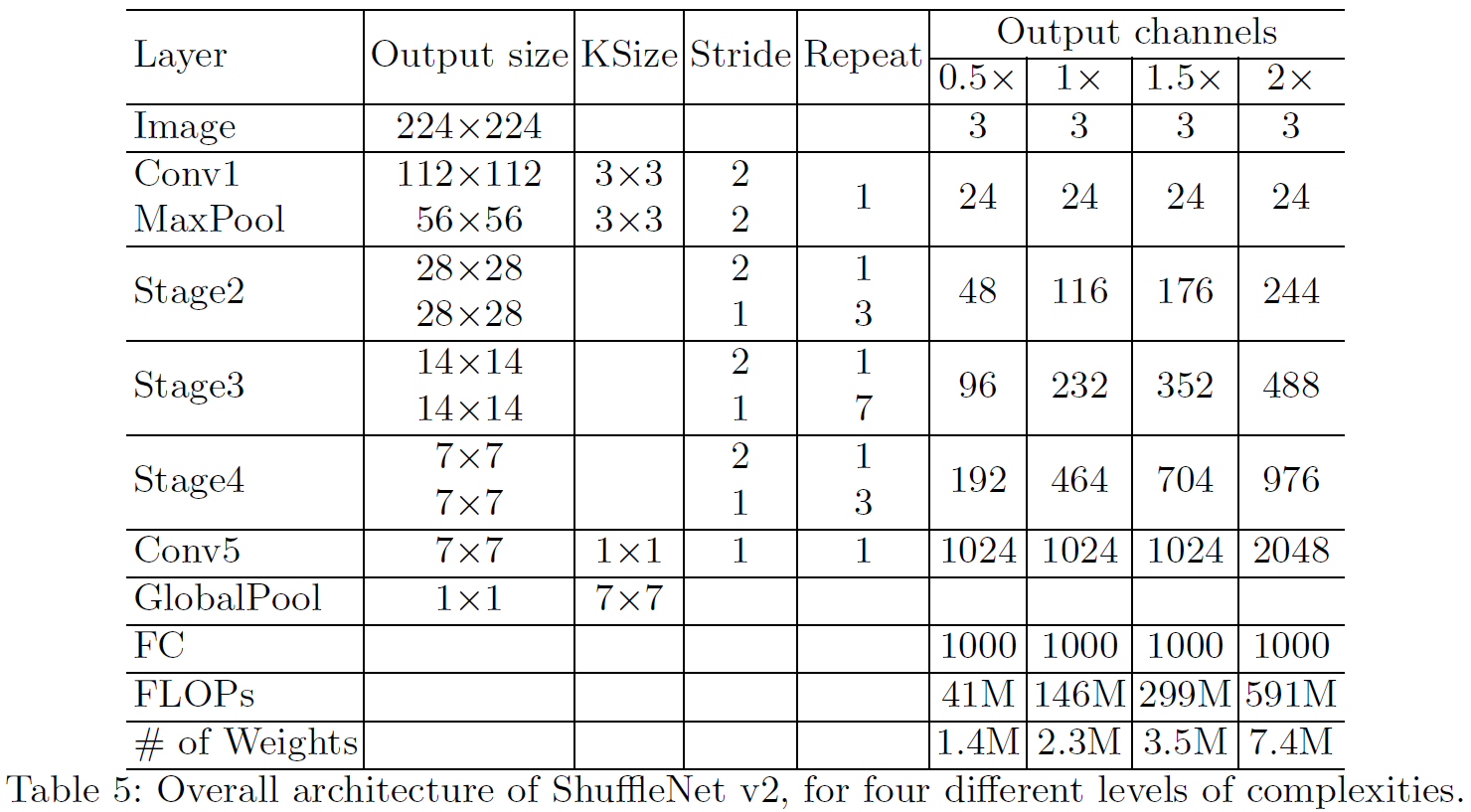
네트워크 구조
Analysis of Network Accuracy
ShuffleNet V2는 효율적이며 성능도 좋음.
더 많은 channel, 더 큰 network를 만들 수 있음.
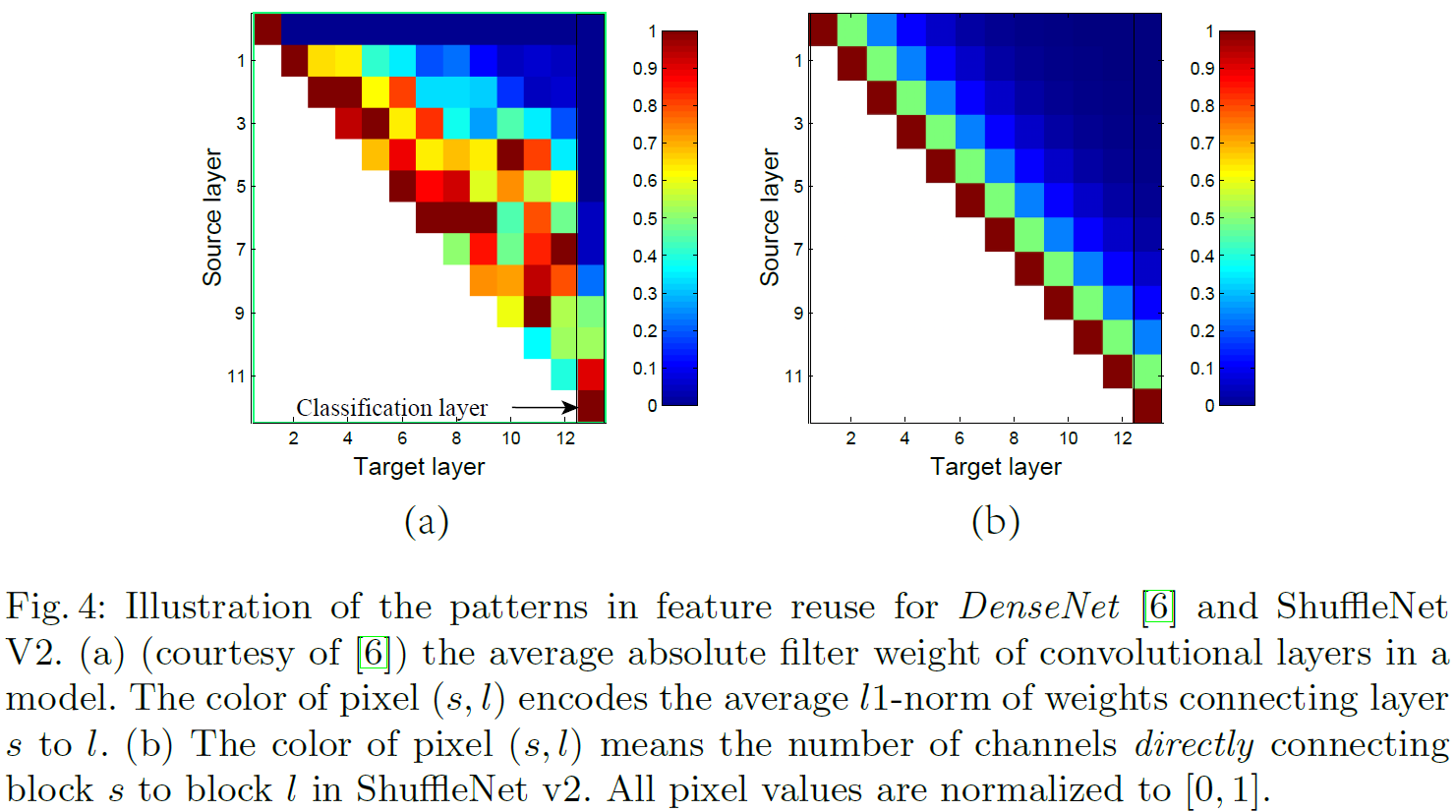
DenseNet 이나 CondenseNet 처럼 feature reuse 과 매우 유사함.
DenseNet의 feature reuse 패턴과 ShuffleNet V2의 feature reuse 패턴 비교.
붉을 수록 Source layer와 Target layer의 연결성이 강하다는 의미.
DenseNet과 같이 ShuffleNet V2에서도 Target layer가 멀어질 수록 연결성이 약함.
Experiment
총 4개의 모델과 비교.
ShuffleNet V1
MobileNet V2
Xception
DenseNet
Accuracy vs. FLOPs
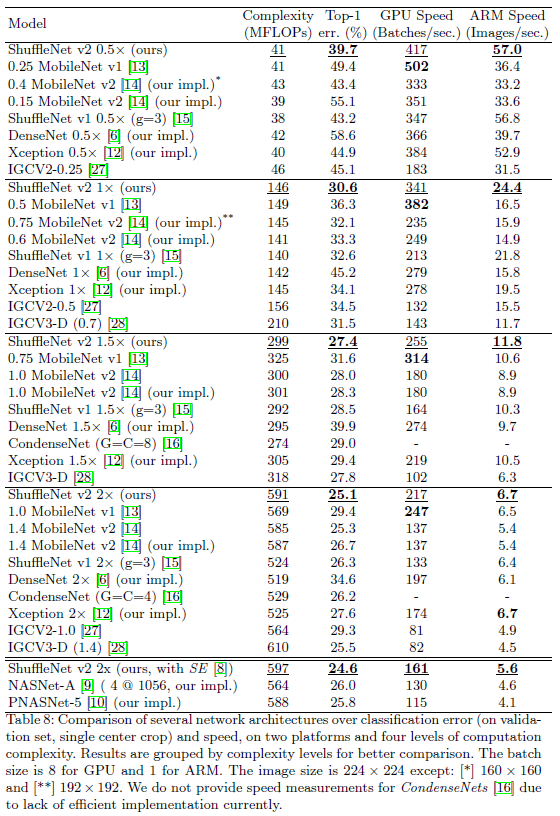
연산량을 40 MFLOPs 로 고정시키고 Network 를 구성한 후 성능 비교. (Table 8 상단)
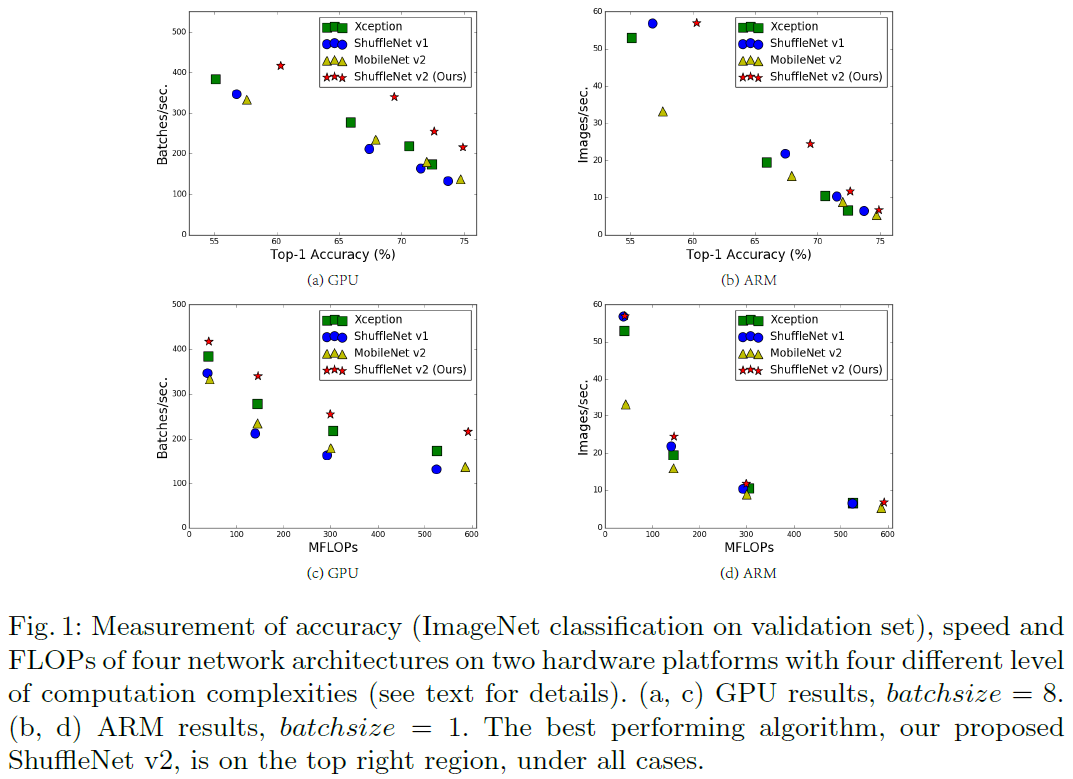
Inference Speed vs. FLOPs/Accuracy
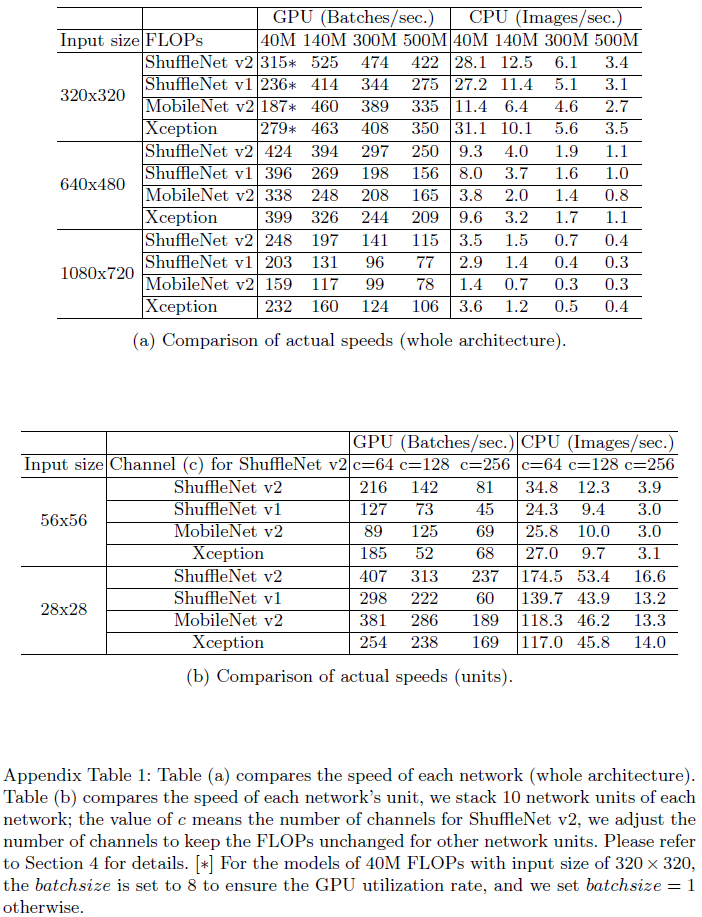
연산량을 특정 값 범위로 고정시키고 runtime 비교. (Fig 1 참조)
Compared with MobileNet v1
MobileNet V1의 경우 Accuracy가 좋지 않으나 GPU runtime은 가장 빠름.
이는 위에서 제시한 가이드 라인을 어느 정도 가장 잘 만족하기 때문.
Compared automatic model search
NAS 는 매우 느리지만 제시한 가이드 라인을 만족하고 speed에 대한 metric을 사용한다면 충분히 좋은 성능을 보일 것.
Compatibility with other methods
Squeeze-and-excitation 과 같은 module과 같이 사용할 수 있음.
속도는 떨어지나 정확도는 상승. (Table 8 하단)
Generalization to Large Models
2GFLOPs 이상의 큰 모델을 생성할 수 있음.
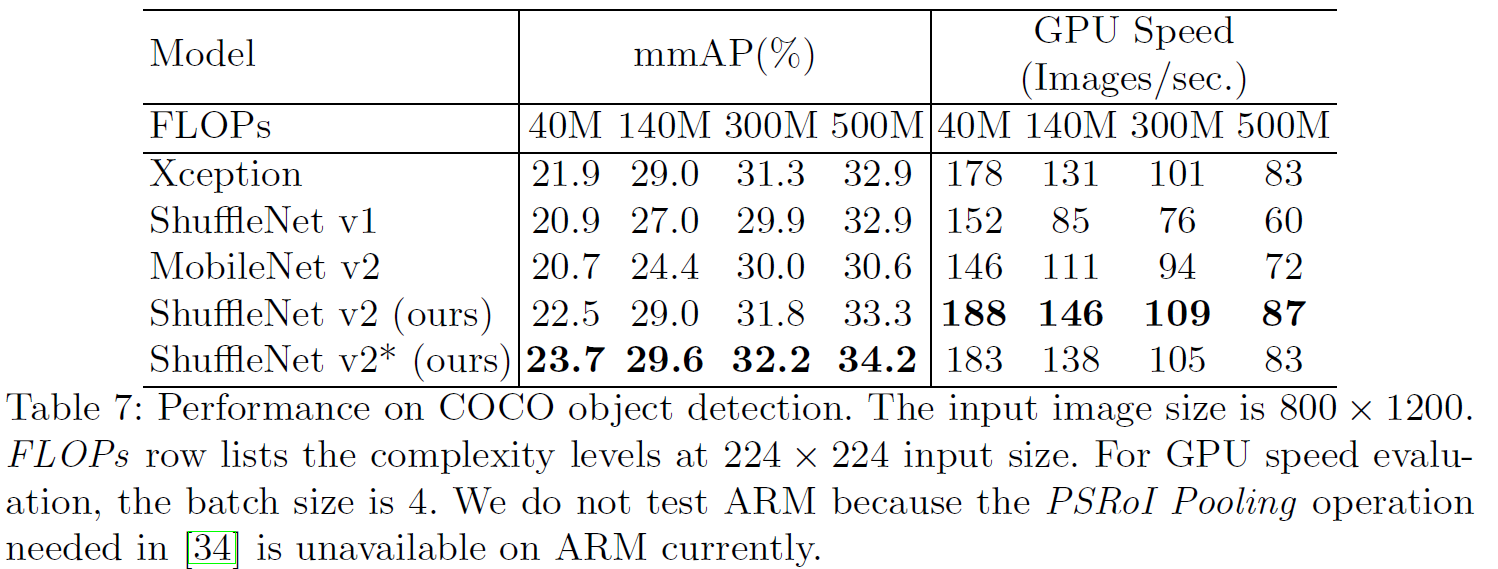
50개의 레이어를 가진 모델을 생성해도 ResNet-50 과 비교하여 적은 연산량, 뛰어난 성능을 보임. (Table 6 상단)
SE module, residual block을 사용하여 더욱 깊게 만들어도 상대적으로 연산량이 적으면서 뛰어난 성능을 보임. (Table 6 하단)