Author: Yunjey Choi, Youngjung Uh, Jaejun Yoo, Jung-Woo Ha
Date: Dec 04, 2019
URL: https://arxiv.org/abs/1912.01865
Image translation 을 잘 하는 Model을 학습하려면 다음 사항을 만족해야함
기존의 방법들은 limited diversity, multiple models(networks)를 다룸.
StarGAN v2는 두 조건 모두 만족.


4개의 Network 로 구성.
Generator (G)
x와 Style code s를 입력으로 받아 새로운 영상을 생성.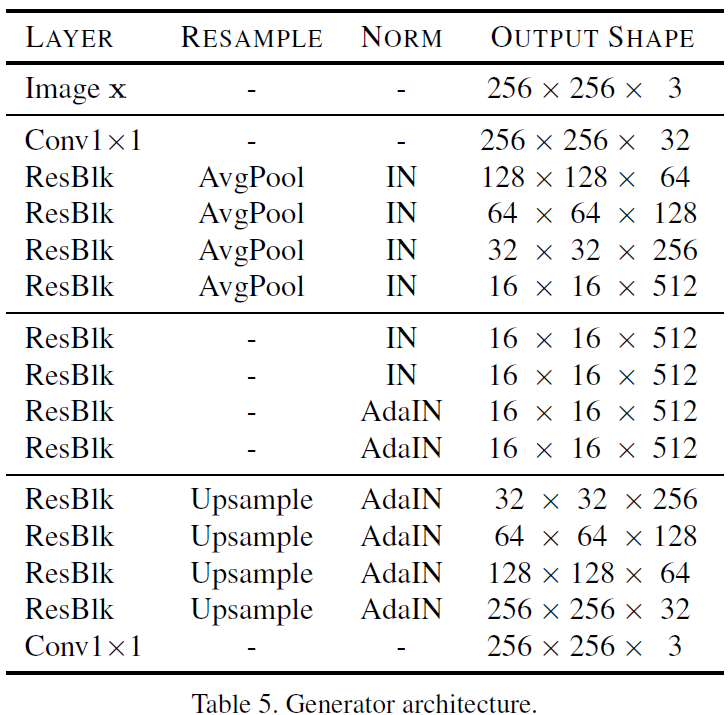
Mapping network (F)
z와 Domain code y를 입력으로 받아 Style code s생성.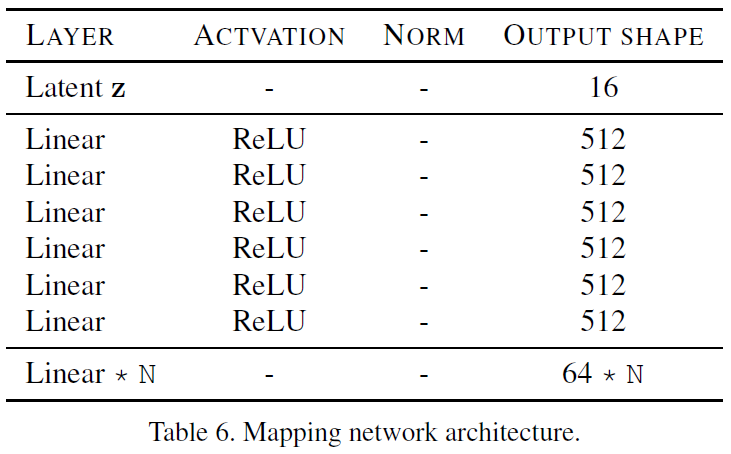
Style encoder (E)
x와 Domain code y를 입력으로 받아 x에서 Style code s를 추출.Discriminator (D)
x를 입력으로 받아 Domain code y와 Real/Fake 분류.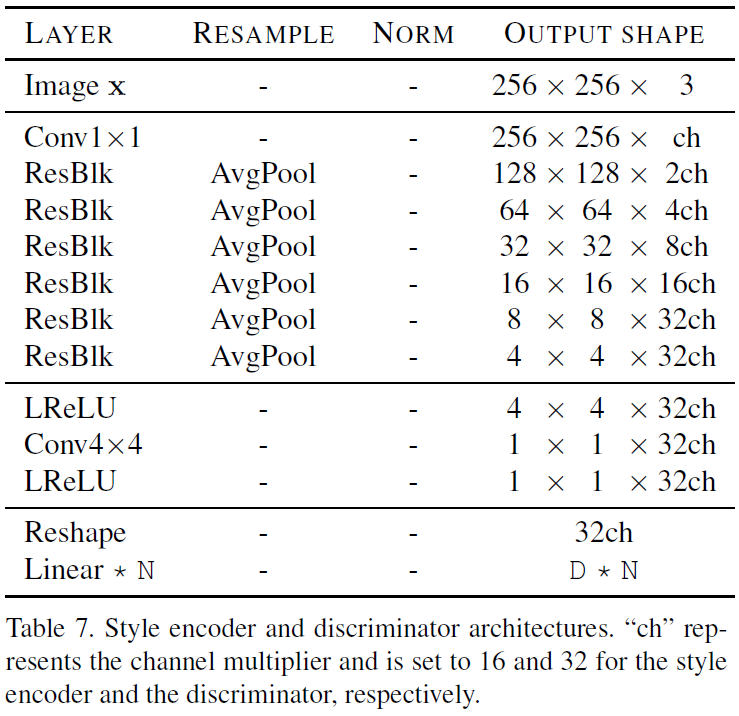
$$\mathcal{L}_{adv}=\mathbb{E}_{\mathrm{x},y}[\log{D_y}(\mathrm{x})] + \mathbb{E}_{\mathrm{x}, \tilde{y}, \mathrm{z}}[\log{(1-D_{\tilde{y}}(G(\mathrm{x}, \tilde{\mathrm{s}})))}$$
G(x, s) 를 Style encoder E 에 넣어 s 추출 후 입력 s와 비교$$\mathcal{L}_{sty}=\mathbb{E}_{\mathrm{x},\tilde{y}, \mathrm{z}}[\parallel\tilde{\mathrm{s}}-E_{\tilde{y}}(G(\mathrm{x}, \tilde{\mathrm{s}}))\parallel_1]$$
G가 다양한 Image를 생성할 수 있도록 Regularization 하는 역할.z1, z2 가 F에 의해 생성된 s1, s2와 입력 x를 G의 입력으로 새로운 영상 생성.$$\mathcal{L}_{ds}=\mathbb{E}_{\mathrm{x},\tilde{y}, \mathrm{z}_1, \mathrm{z}_2}[\parallel G(\mathrm{x}, \tilde{\mathrm{s}}_1) - G(\mathrm{x}, \tilde{\mathrm{s}}_2) \parallel_1]$$
E(x)로 추출된 s를 이용하여 x'로 reconstruction 한 후 L1 Norm 계산.$$\mathcal{L}_{cyc}=\mathbb{E}_{\mathrm{x}, y, \tilde{y}, \mathrm{z}}[\parallel \mathrm{x} - G(G(\mathrm{x}, \tilde{\mathrm{s}}), \hat{\mathrm{s}})\parallel_1]$$
Full objective
$$\mathcal{L}_D = -\mathcal{L}_{adv} \ \mathcal{L}_{F, G, E}=\mathcal{L}_{adv} + \lambda_{sty} \mathcal{L}_{sty} - \lambda_{ds} \mathcal{L}_{ds} + \lambda_{cyc} \mathcal{L}_{cyc}$$
| Dataset | sty | ds | cyc |
|---|---|---|---|
| CelebA-HQ | 1 | 1 | 1 |
| AFHQ | 0.3 | 1 | 0.1 |
Baselines
Datasets
Evaluation metrics