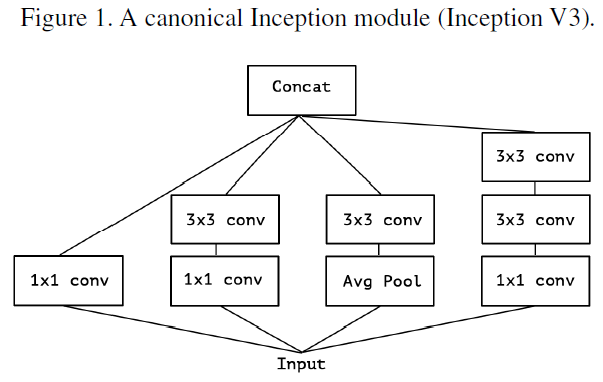
Inception 모델은 위와 같은 모듈을 Stack 한 것. VGG-Style 네트워크는 단순히 Convolution layer를 Stack.
실험적으로 Inception-style 이 VGG-style보다 적은 parameter로 다양한, 많은 feature를 학습 할 수 있다는 것을 보임.
1.1 The Inception hypothesis
Convolution layer는 3차원 공간에서 filter를 학습하려고 함.
Single Convolution kernel 은 채널의 correlation과 공간의 correlation 을 동시에 mapping 함.
Inception 모듈은 채널, 공간의 correlation 을 독립적으로 나타낼 수 있도록 연산을 분해. -> 쉽고 효율적인 프로세스를 만듦.
Inception의 가설은 채널 채널, 공간의 correlation 이 분리되어 있으므로 동시에 매핑하는 것은 좋지 않다는 것.
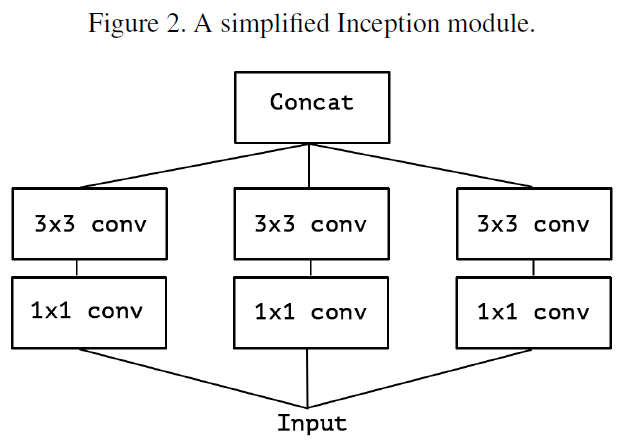
Figure 2는 3x3 conv와 1x1 conv만 사용한 단순화한 Inception 모듈.
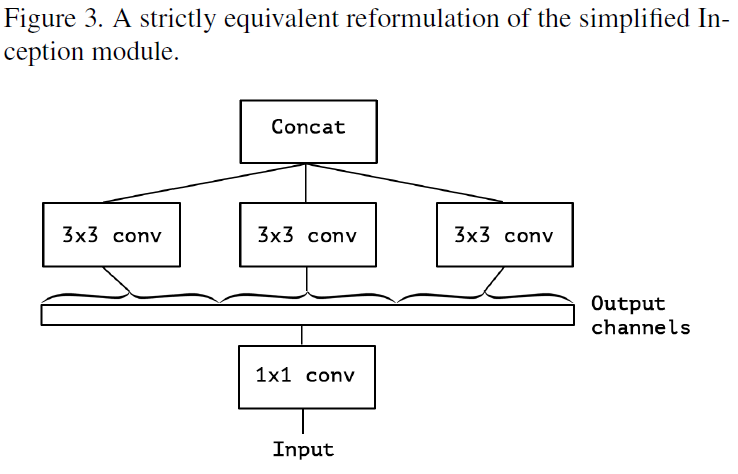
Figure 3은 Figure 2의 Inception 모듈에서 하나의 큰 1x1 Convolution과 3x3 Convolution들로 재구성한 것.
이 방법이 Inception 의 가설보다 뛰어난 가설을 만드는 것이 합리적인 것일지, 채널과 공간을 독립적으로 매핑할 수 있는지 의문.
1.2 The continuum between convolutions and separable convolutions
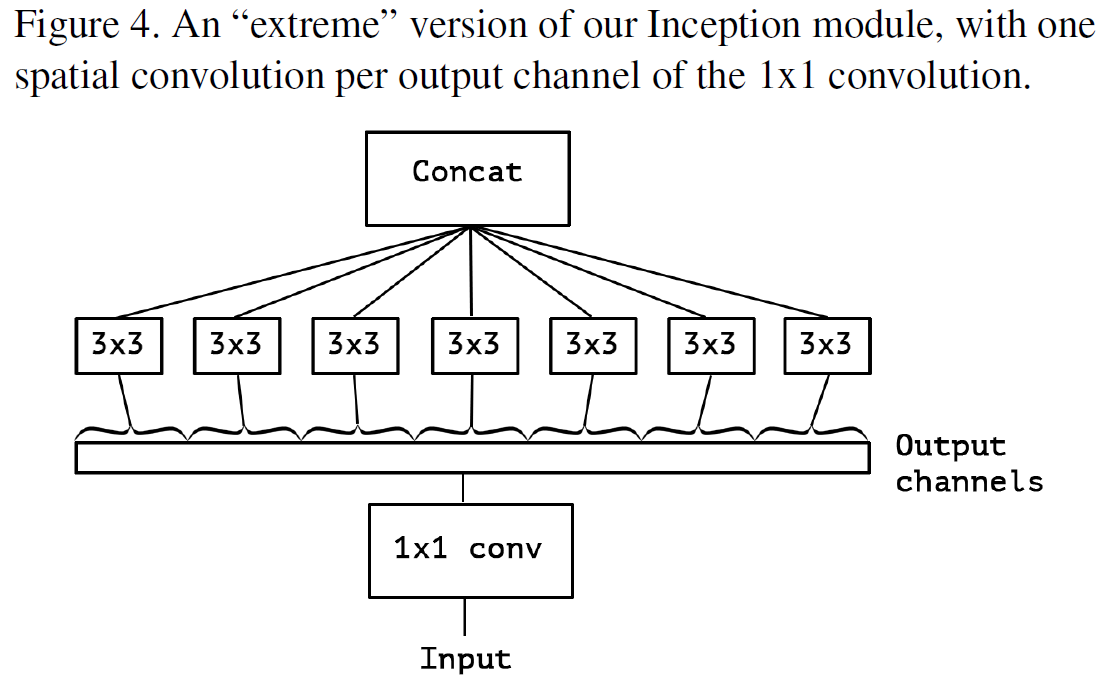
Figure 4 처럼 Inception 모듈 구성.
1x1 Convolution 적용하여 채널의 correlation 매핑, 그 후 각각의 channel별로 공간의 correlation 매핑
이를 An “extreme” version of an Inception module 이라고 칭함.
TensorFlow 프레임워크에 Depthwise Separable Convolution 연산과 거의 동일함.
TensorFlow나 Keras 프레임워크에 있는 Depthwise Separable Convolution (Separable Convolution 라고도 불림.) 은 각 channel 별로 3x3 Convolution 적용 후 채널간의 1x1 Convolution 적용.
영상처리 분야에서 사용하는 Separable Convolution 과 혼동하면 안됨, 이 연산은 공간적 분리를 하는 Convolution.
비교
Extream
Depthwise Separable
연산순서
pointwise–>channelwise
channelwise–>pointwise
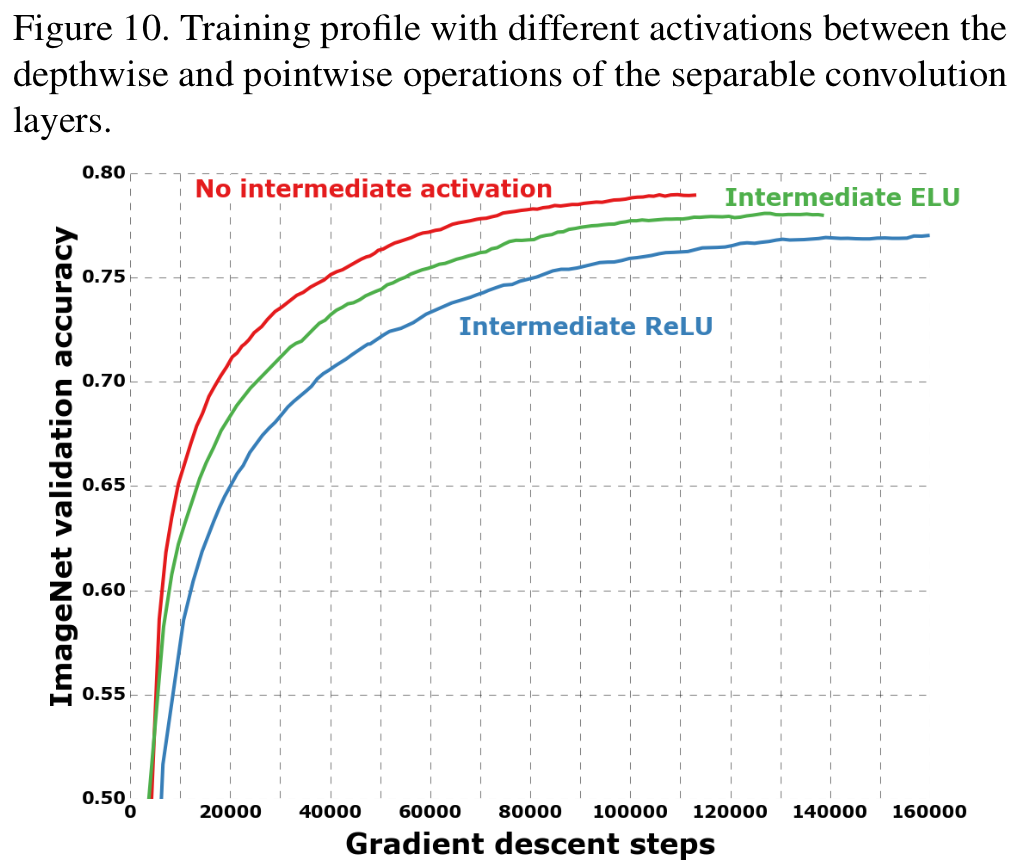
비선형성
Presence
Absence
2. Prior work
VGG-16 과 같은 구조가 xception 과 유사.
Inception 구조는 가지치기의 이점을 보여줌.
Depthwise separable convolution는 경량화에도 적합.
TensorFlow에는 이미 구현되어있음.
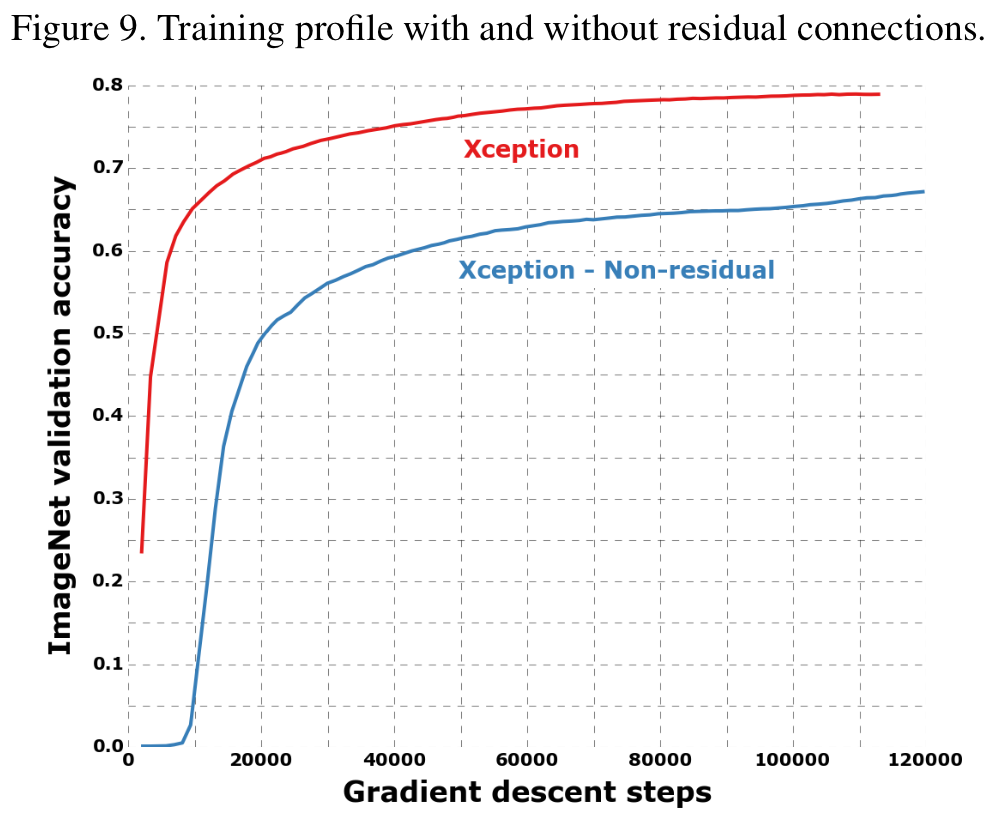
Residual connection 을 광범위하게 사용.
3. The Xception architecture
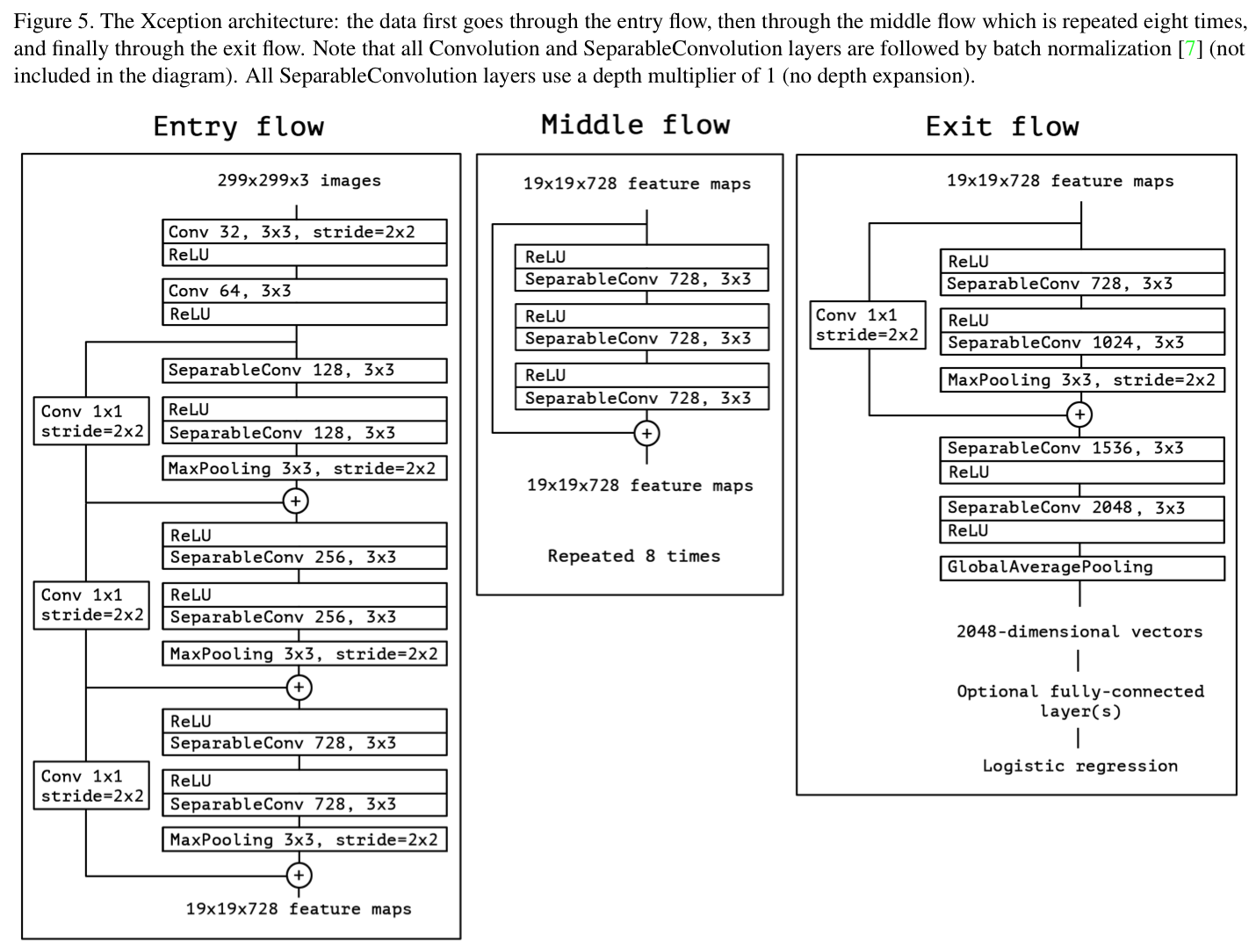
Figure 5 와 같은 구조 제안.
처음과 마지막을 제외하곤 linear residual module 사용.
총 36개의 convolution layer로 구성.
매우 단순한 구조.
4. Experimental evaluation
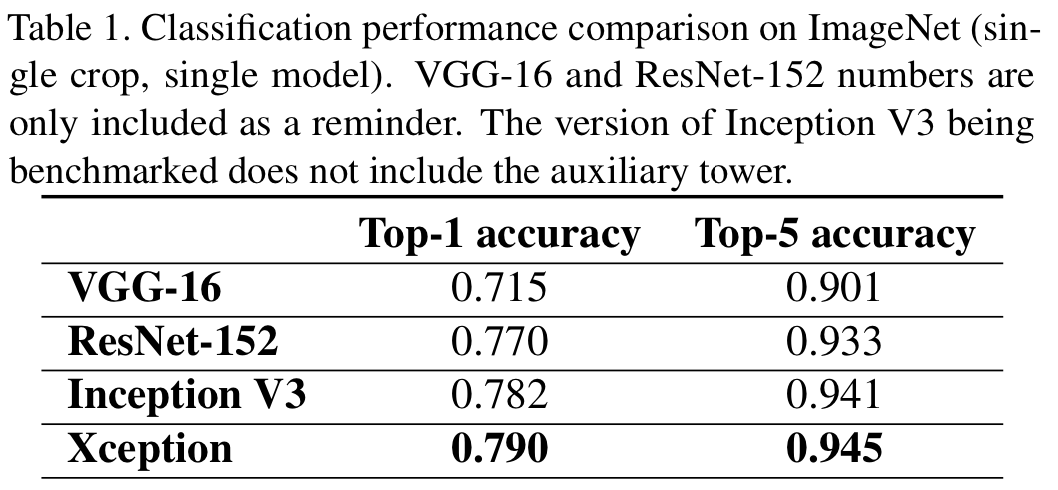
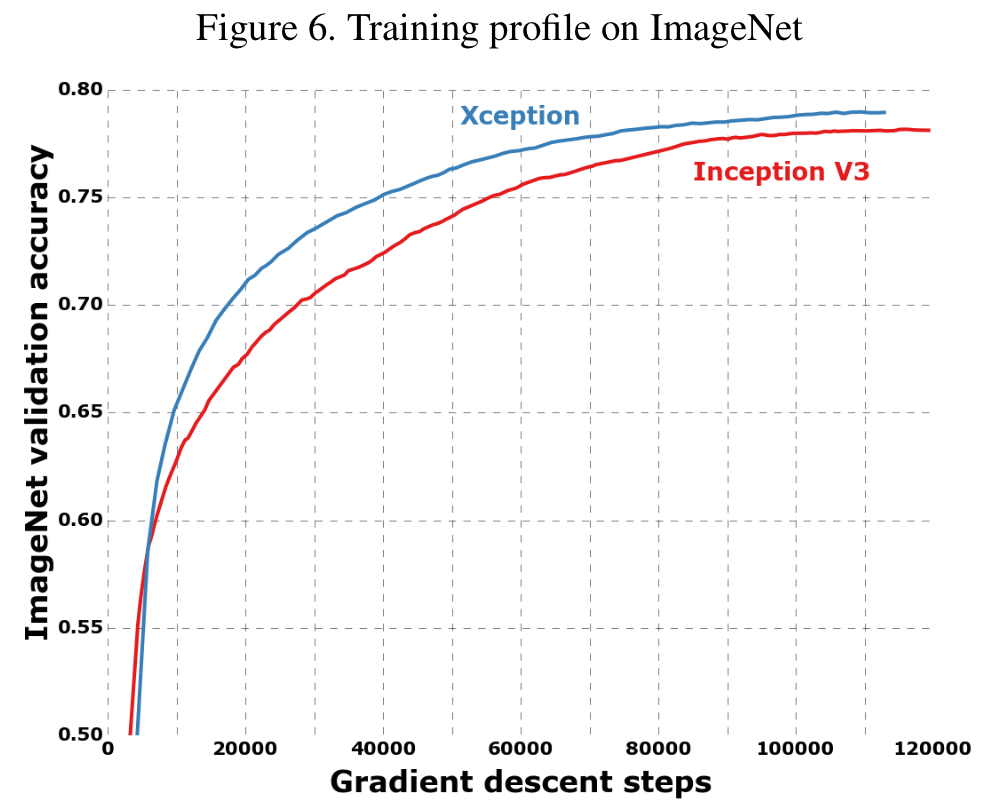
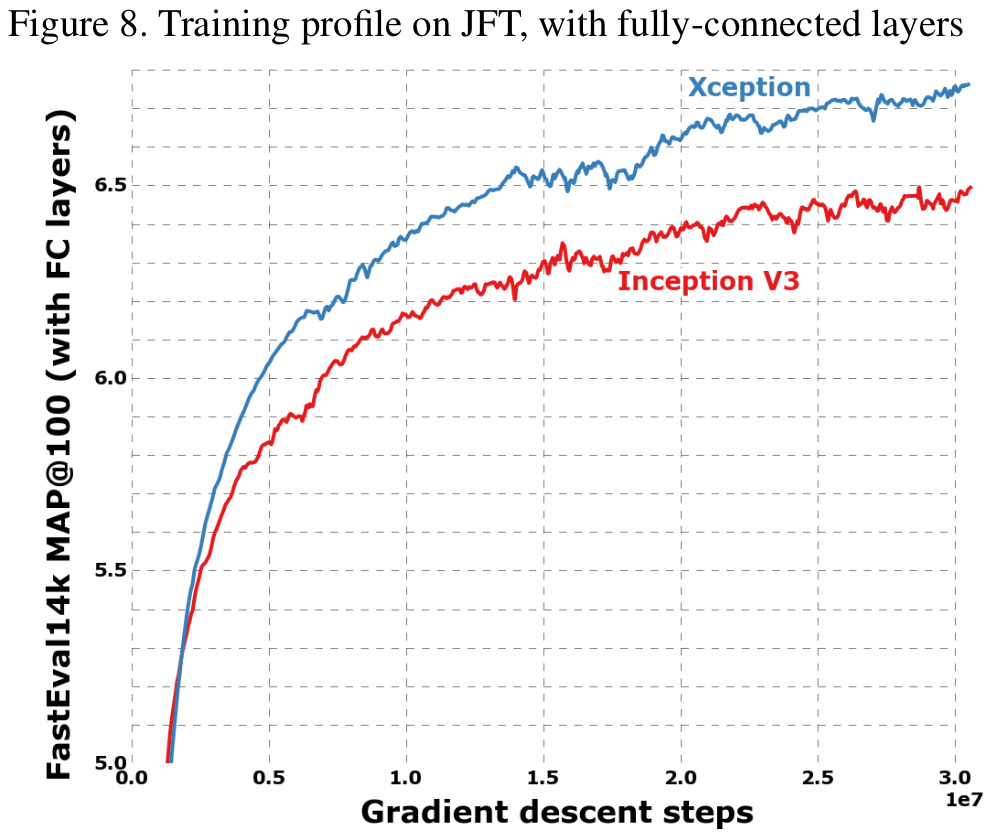
Xception과 Inceotion V3 비교.
Parameters가 비슷. 네트워크 규모에 대한 차이를 없애기 위함.
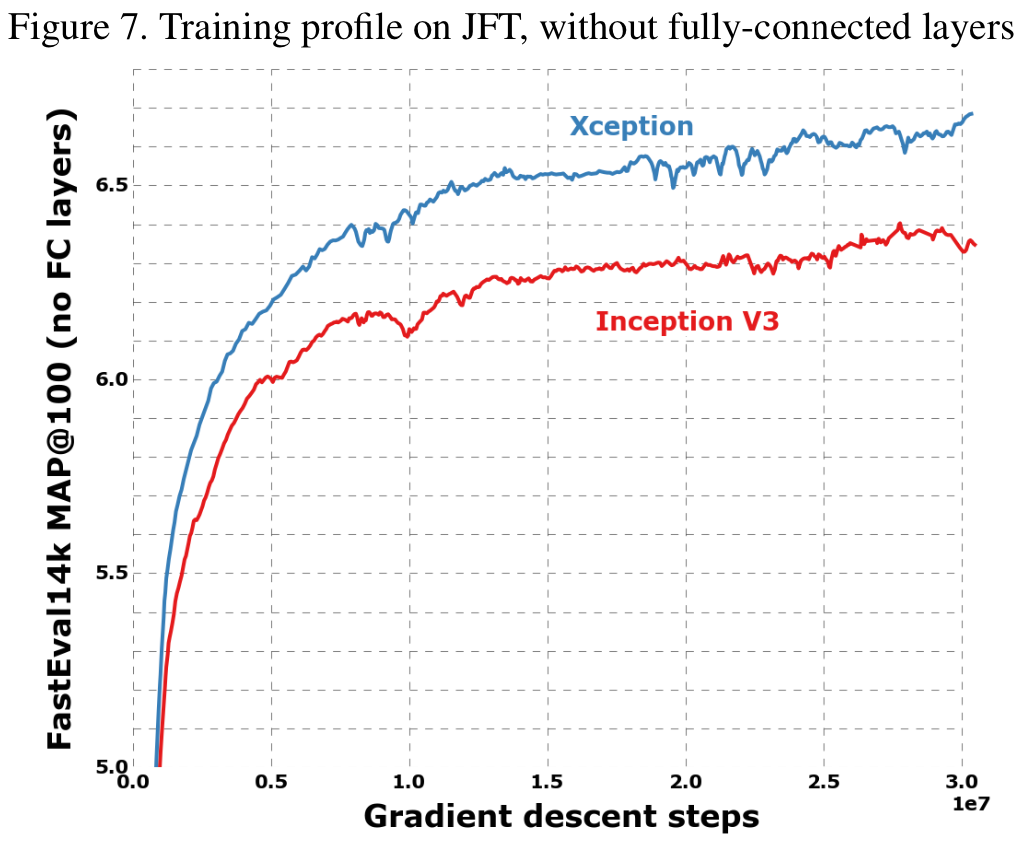
ImageNet과 JFT dataset 이용.
4.1 The JFT dataset
그냥…JFT 데이터 설명…
Google 데이터 중 하나
JFT 로 학습, FastEval14k dataset으로 성능 비교.
4.2 Optimization configuration
각 방법에 대해서 다음과 같은 설정으로 Xception, Inception V3 모두 학습