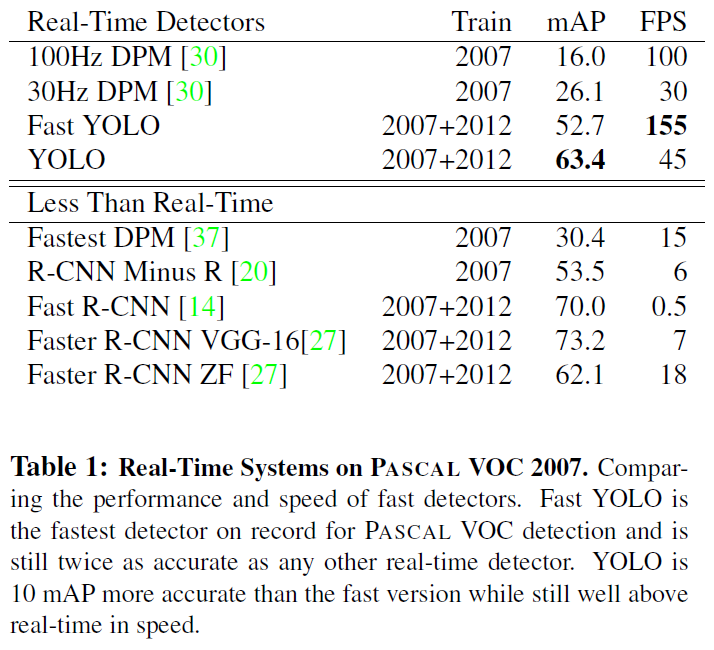
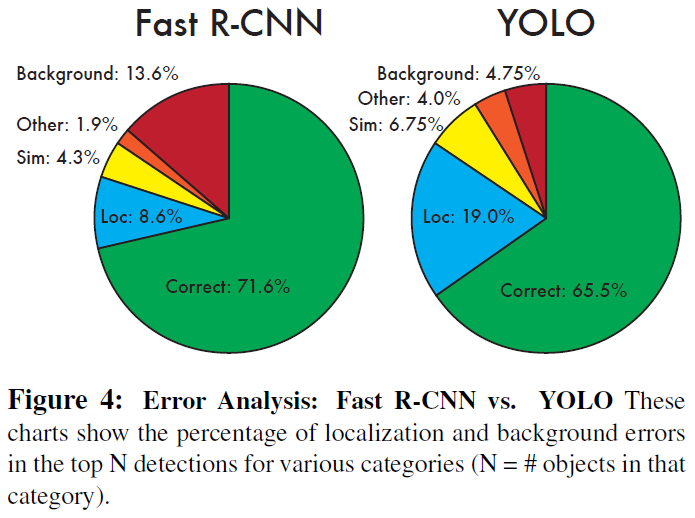
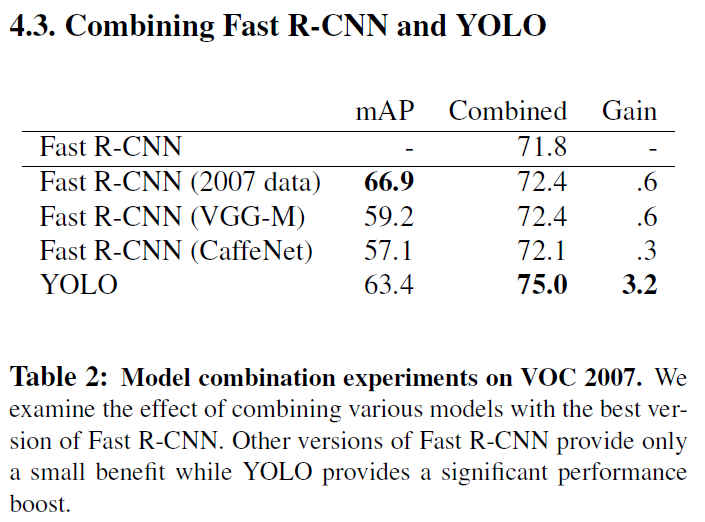
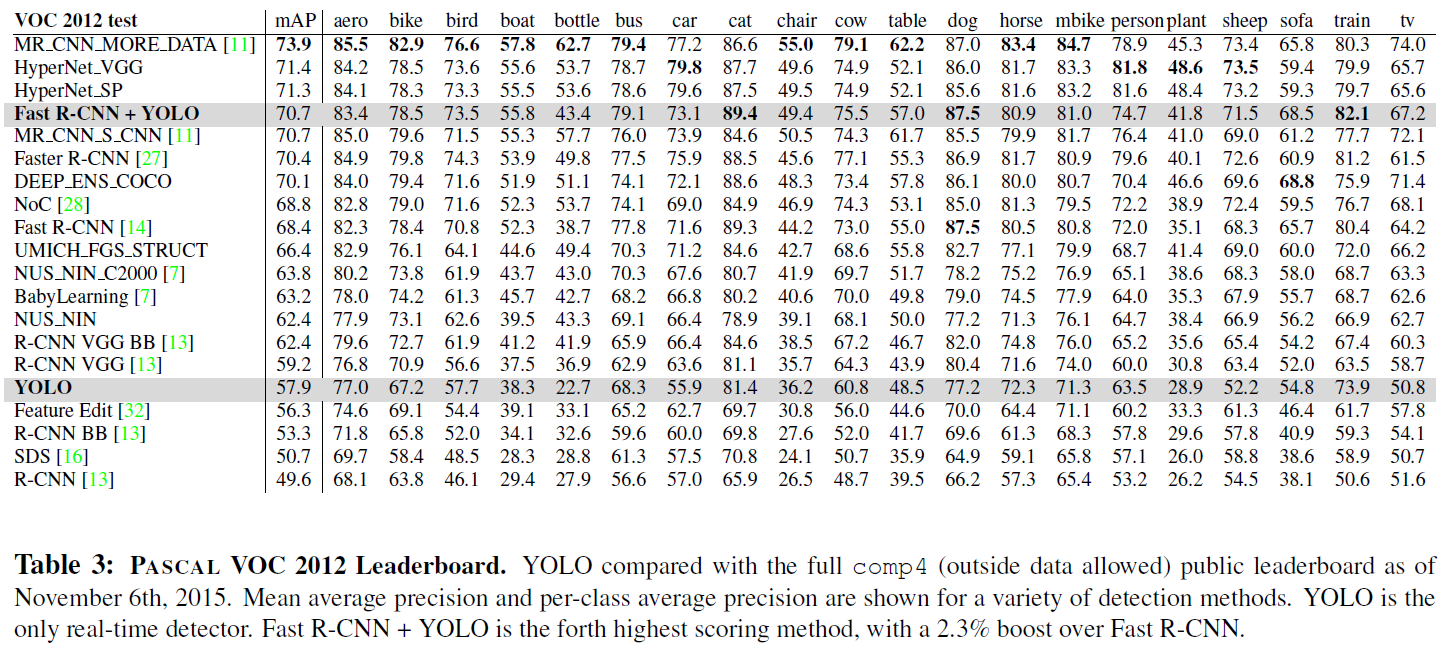
편의상 bounding box -> bbox

복잡하지 않은 pipeline과 빠른 inferenc time.
이미지 전체를 이용한 prediction
Object의 general한 representations 학습.
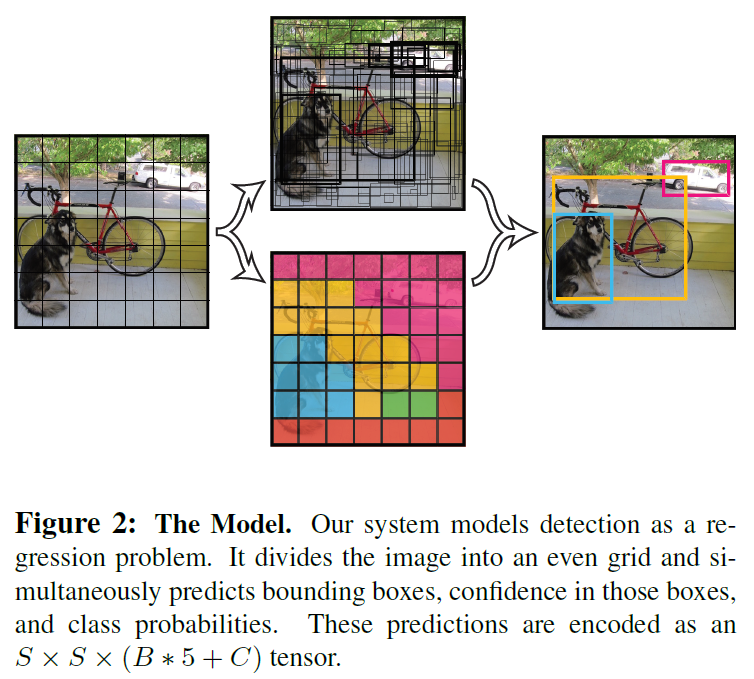
입력 이미지를 S x S grid로 나눔.
각 grid cell은 B개의 bbox의 정보(x, y, w, h, confidence score), 해당 grid cell의 Class probabilities 정보를 가짐.
bbox의 정보
Class Probabilities 정보
C개의 class에 대한 conditional class probabilities, \(Pr(Class_i \mid Object)\)
Test 시에는 Conditional class probabilities와 individual box confidence score를 곱했다고 함.
\(Pr(Class_i|Object) = Pr(Object) * IOU^{truth}_{pred} = Pr(Class_i) * IOU^{truth}_{pred}\)
bbox 별로 class confidence score를 알 수 있음.
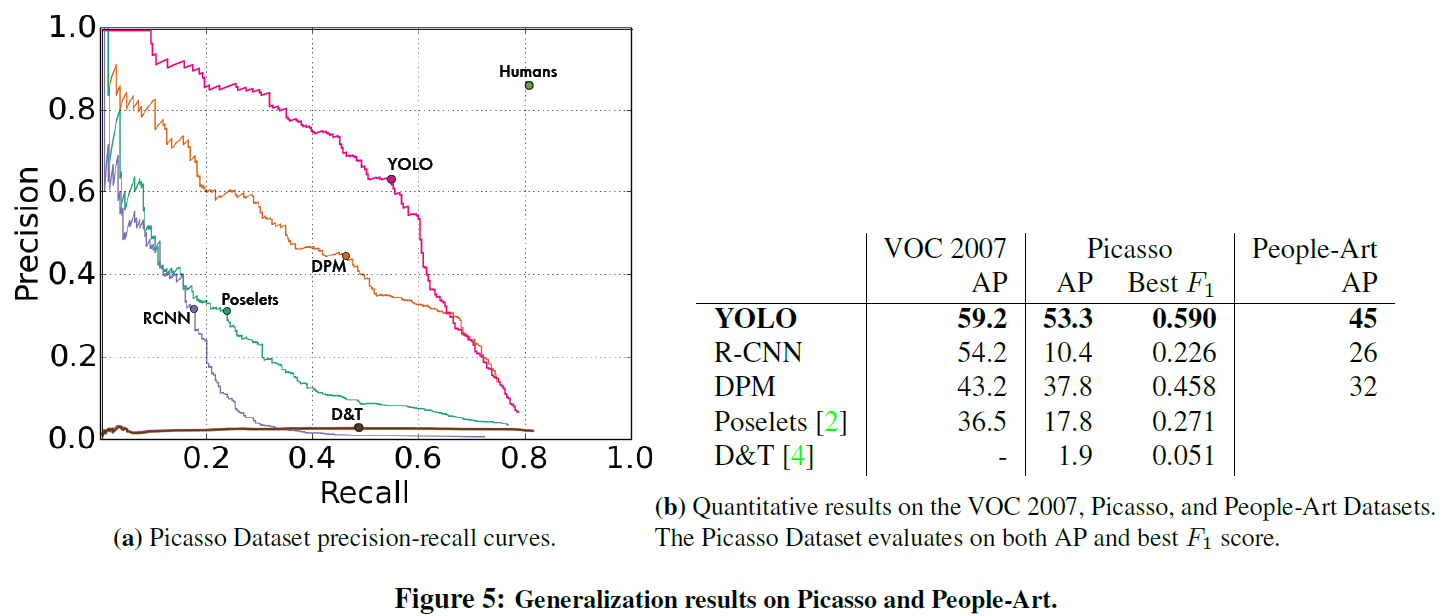
PASCAL VOC 로 평가. S = 7, B = 2, C = 20
최종 출력은 7 x 7 x 30 의 tensor.
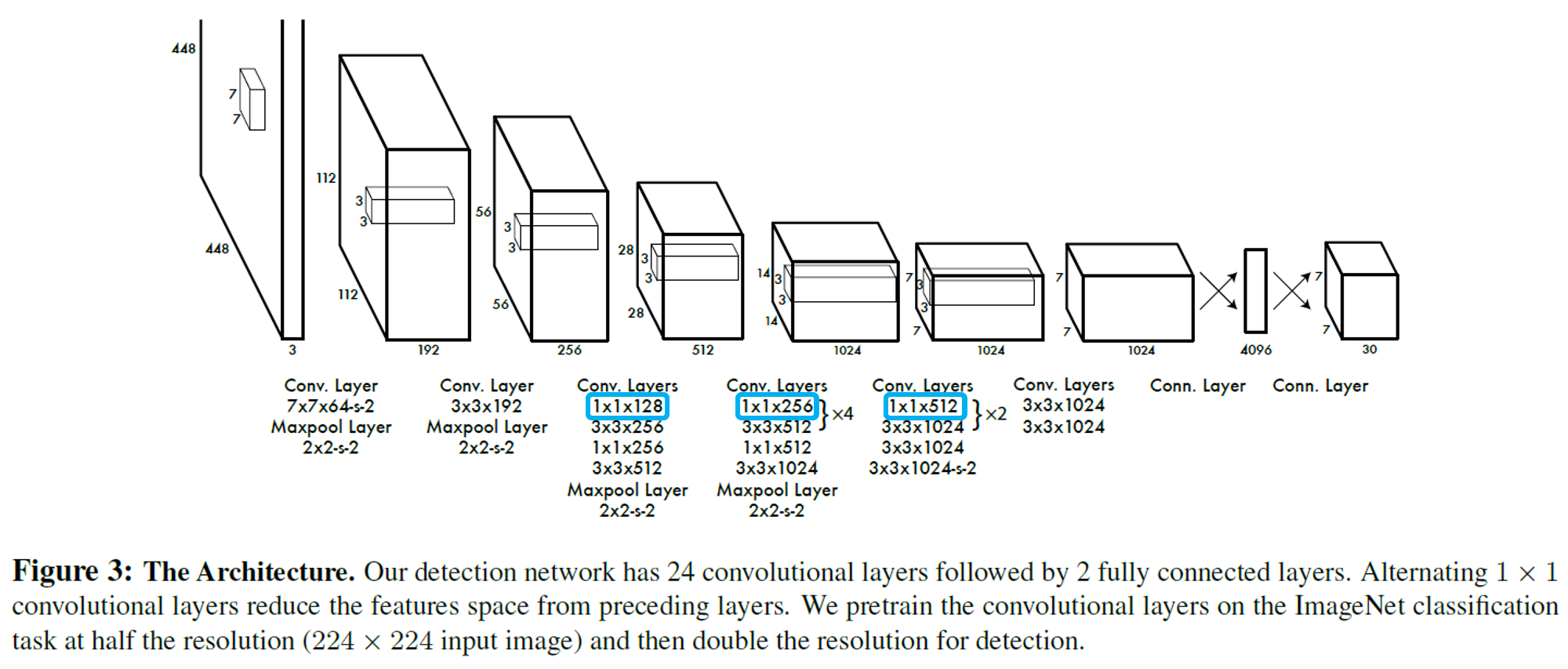
앞 단의 20개의 Convolution layer(Feature Extractor)를 ImageNet 1000-class competition 데이터(224 x 224)로 Pretrain.
20번째 Convolution layer 뒤에 Average Pooling, Fully Connected Layer.
ImageNet 2012 validation set으로 top-5 accuracy 88% 정도..
Pretrain 후 Detector 부분 추가 후 입력 크기를 448 x 448 로 높여서 학습 진행.
Bounding Box의 width, height 값은 이미지의 width, height로 normalize 하여 0 ~ 1 사이 값을 같도록 함.
Bounding Box의 x, y 값은 특정 grid cell의 left top으로부터 offset 값. 0 ~ 1 사이 값을 같도록 함.
마지막 layer는 linear activation function 사용.
다른 layer는 leaky ReLU 사용. $$\phi(x)=\begin{cases}x,&if;x >0\\ {0.1}x, & otherwise\end{cases}$$
Optimization이 쉬운 Sum-Squared Error 를 사용.
이미지의 대부분 grid cell이 object 를 가지고 있지 않기 때문에 Confidence Score가 0 에 수렴.
이 상황에선 object를 가지고 있는 grid cell의 gradient를 압도할 수 있음.
이를 해결하기 위해 Bbox coordinate loss와 No object의 confidence loss 에 대해 weight 를 부여.
\(\lambda_{coord} = 5\) and \(\lambda_{noobj} = 0.5\).
Sum-Squared Error는 large boxes와 small boxes 를 동일하게 평가.
large boxes 에 대해서 중요성을 반영하기 위해 width, height 는 square root 사용.
$$\lambda_{coord}\sum^{S^2}_{i=0}\sum^B_{j=0}\mathbb{I}^{obj}{ij}(x_i-\hat{x}i)^2+(y_i-\hat{y}i)^2$$ $$+\lambda{coord}\sum^{S^2}_{i=0}\sum^B{j=0}\mathbb{I}^{obj}{ij}(\sqrt{w_i}-\sqrt{\hat{w}i})^2 + (\sqrt{h_i}-\sqrt{\hat{h}i})^2$$ $$+ \sum^{S^2}_{i=0}\sum^B{j=0}\mathbb{I}^{obj}{ij}(C_i - \hat{C}i)^2$$ $$ + \lambda{noobj}\sum^{S^2}_{i=0}\sum^B_{j=0}\mathbb{I}^{noobj}_{ij}(C_i - \hat{C}i)^2 $$ $$ + \sum^{S^2}_{i=0}\mathbb{I}^{obj}_{i}\sum^B{c\in{classes}}(p_i(c) - \hat{p}_i(c))^2 $$
\(\mathbb{I}^{obj}_{i}\) : Object가 존재하는 Grid Cell i.
\(\mathbb{I}^{obj}_{ij}\) : Object가 존재하는 Grid Cell i의 Bounding Box j.
Train 관련 Parameter