
오늘은 Weights & Biases 의 기능중 하나인 sweep에 대해서 알아보려고 합니다.
sweep은 정말 쉽게 말해서 Hyper parameter search and model optimization 을 쉽게 할 수 있도록 해주는 기능입니다.
자세한 장단점에 대해서 궁금하신 분은 여기를 눌러서 확인해주세요!
그럼 사용법을 알아보겠습니다.
model.py와 train.py 이렇게 두 개의 스크립트를 작성했습니다.# model.py
import tensorflow as tf
from tensorflow.keras import models, layers, losses, optimizers
from tensorflow.keras.applications import DenseNet121, DenseNet169, DenseNet201
from tensorflow.keras.applications import VGG16, VGG19, Xception, InceptionResNetV2, InceptionV3
from tensorflow.keras.applications import MobileNet, MobileNetV2, NASNetLarge, NASNetMobile
from tensorflow.keras.applications import ResNet50, ResNet101, ResNet152, ResNet50V2, ResNet101V2, ResNet152V2
model_dict = {
"vgg16": VGG16,
"vgg19": VGG19,
"resnet50": ResNet50,
"resnet101": ResNet101,
"resnet152": ResNet152,
"resnet50v2": ResNet50V2,
"resnet101v2": ResNet101V2,
"resnet152v2": ResNet152V2,
"densenet121": DenseNet121,
"densenet169": DenseNet169,
"densenet201": DenseNet201,
"mobilenet": MobileNet,
"mobilenetv2": MobileNetV2,
"xception": Xception,
"inceptionresnetv2": InceptionResNetV2,
"inceptionv3": InceptionV3,
"nasnetlarge": NASNetLarge,
"nasnetmobile": NASNetMobile
}
def build_model(config, num_classes=10, name="model"):
assert config.model_name.lower() in model_dict.keys(), f"Please, check pretrained model list {list(model_dict.keys())}"
last_activation = "softmax" if num_classes > 1 else "sigmoid"
base_model = model_dict[config.model_name.lower()](include_top=False, weights="imagenet", pooling="avg")
if config.freeze:
base_model.trainable = False
output = layers.Dropout(config.dropout, name=f"{name}_dropout")(base_model.output)
output = layers.Dense(num_classes, last_activation, name=f"{name}_output")(output)
model = models.Model(base_model.input, output, name=name)
return model
#train.py
import os
import cv2 as cv
import numpy as np
import tensorflow as tf
from tensorflow.keras import optimizers, utils
from model import *
import wandb
from wandb.keras import WandbCallback
tf.random.set_seed(42)
hyperparameter_defaults = dict(
model_name="mobilenet",
dropout = 0.5,
freeze = 1,
batch_size = 128,
learning_rate = 0.001,
epochs = 5,
GPUs="0"
)
wandb.init(project="usage_02", config=hyperparameter_defaults)
config = wandb.config
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]=config.GPUs
# For Efficiency
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
print(e)
# Data Prepare
URL = 'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz'
path_to_zip = tf.keras.utils.get_file('flower_photos.tgz', origin=URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'flower_photos')
category_list = [i for i in os.listdir(PATH) if os.path.isdir(os.path.join(PATH, i)) ]
print(category_list)
num_classes = len(category_list)
img_size = 128
def read_img(path, img_size):
img = cv.imread(path)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
img = cv.resize(img, (img_size, img_size))
return img
imgs_tr = []
labs_tr = []
imgs_val = []
labs_val = []
for i, category in enumerate(category_list):
path = os.path.join(PATH, category)
imgs_list = os.listdir(path)
print("Total '%s' images : %d"%(category, len(imgs_list)))
ratio = int(np.round(0.05 * len(imgs_list)))
print("%s Images for Training : %d"%(category, len(imgs_list[ratio:])))
print("%s Images for Validation : %d"%(category, len(imgs_list[:ratio])))
print("=============================")
imgs = [read_img(os.path.join(path, img),img_size) for img in imgs_list]
labs = [i]*len(imgs_list)
imgs_tr += imgs[ratio:]
labs_tr += labs[ratio:]
imgs_val += imgs[:ratio]
labs_val += labs[:ratio]
imgs_tr = np.array(imgs_tr)/255.
labs_tr = utils.to_categorical(np.array(labs_tr), num_classes)
imgs_val = np.array(imgs_val)/255.
labs_val = utils.to_categorical(np.array(labs_val), num_classes)
print(imgs_tr.shape, labs_tr.shape)
print(imgs_val.shape, labs_val.shape)
# Build Network
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = build_model(config, num_classes)
loss = 'binary_crossentropy' if num_classes==1 else 'categorical_crossentropy'
model.compile(optimizer=optimizers.Adam(config.learning_rate), loss=loss, metrics=['acc'])
# Training Network
model.fit(x=imgs_tr, y=labs_tr, batch_size=config.batch_size, epochs=config.epochs,
callbacks = [WandbCallback()],
validation_data=(imgs_val, labs_val))
python train.py
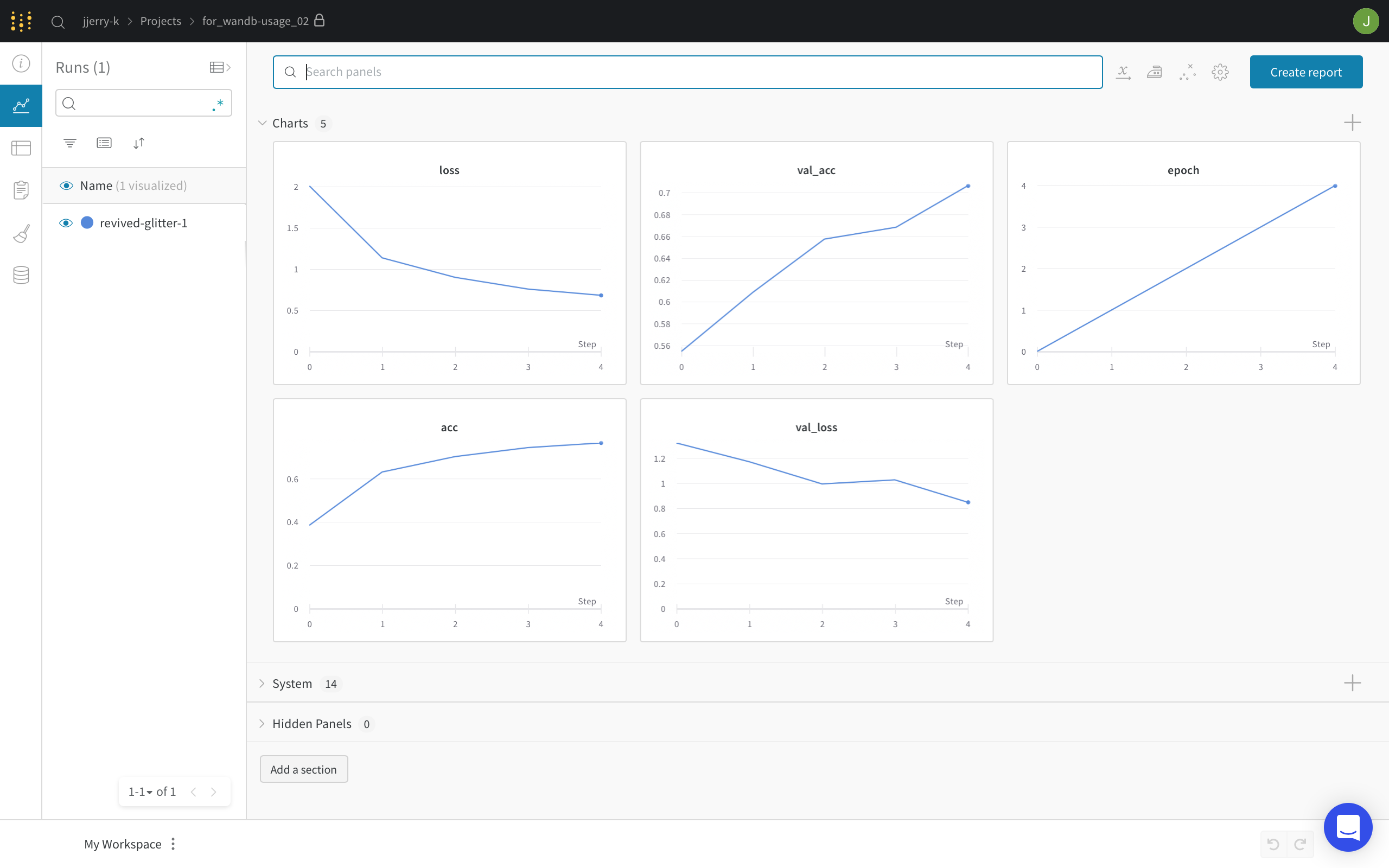
그 후에 Weights & Biases 로 가보면 다음과 같이 프로젝트가 만들어진 것을 확인 할 수 있습니다.
프로젝트 창에서 왼쪽에 빗자루 모양 아이콘을 누른 후에 오른쪽 상단에 Create sweep 를 눌러줍니다. ****
그러면 다음과 같은 창이 나오는데요. 이제 hyper parameter search를 어떻게 할건지 세팅하는 단계입니다.
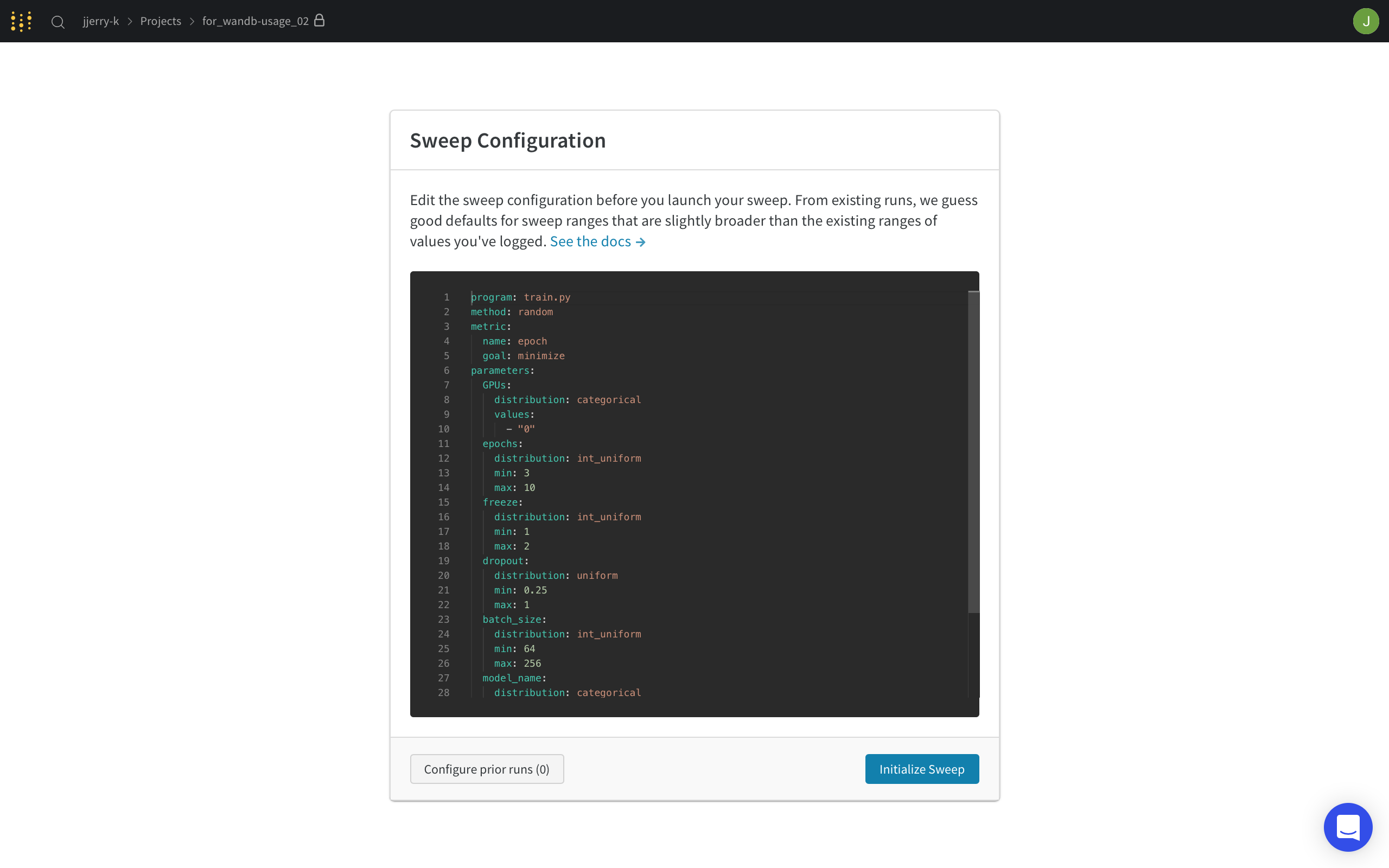
저는 다음과 같이 세팅을 했습니다.
이렇게 하면 grid search…니까….
2 * 5 * 3 * 2 * 3 = 180 개의 결과가 나오겠군요…
program: train.py
method: grid
metric:
name: loss
goal: minimize
parameters:
GPUs:
value: "0"
epochs:
value: 10
freeze:
values: [0, 1]
dropout:
values: [0.1, 0.2, 0.4, 0.5, 0.7]
batch_size:
values: [64, 128, 256]
model_name:
values: [mobilenet, mobilenetv2]
learning_rate:
values: [0.001, 0.005, 0.0005]
그리고 Initialize Sweep 를 눌러줍니다! 그러면 다음과 같은 화면이 나올거에요!
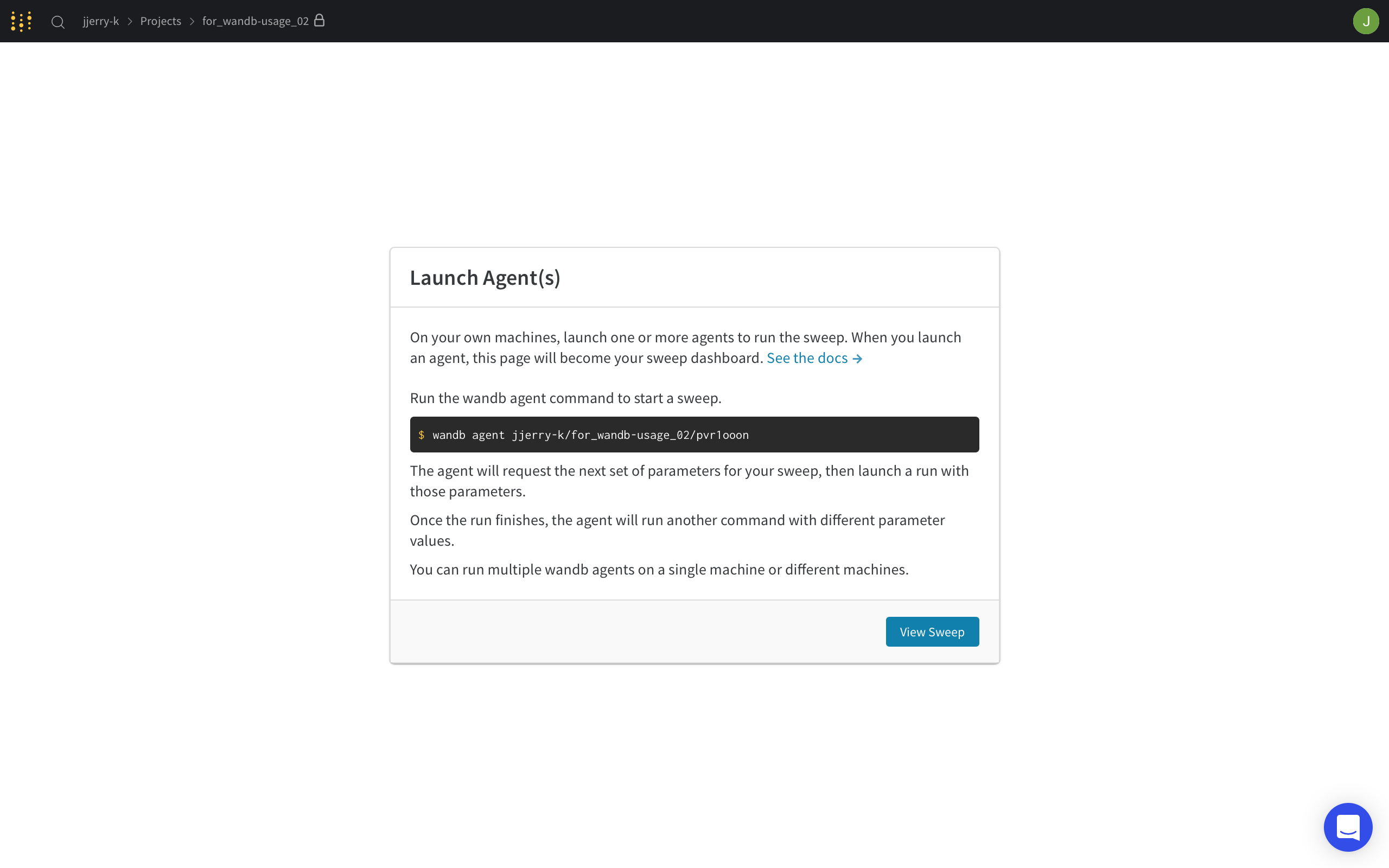
가운데에 적혀있는 커맨드를 터미널에서 실행시켜줍니다!
wandb agent {sweep-id}
그러면 터미널에 wandb: Starting wandb agent 🕵️ 이런 문구와 함께 세팅대로 Network를 학습하게 됩니다!
이제 잠시 티타임을…가집니다.. (잠깐이 아닐 수도 있음..)

Weights & Biases 화면에서 View Sweep 을 눌러주세요!
그리고 좌측에 Plot 아이콘을 누르면 다음과 같은 화면이 나옵니다!
원래는 위에 Chart Panel 있는데 접어놨습니다.
이 Panel은 기본적으로 세 개의 그래프로 구성되어 있습니다.
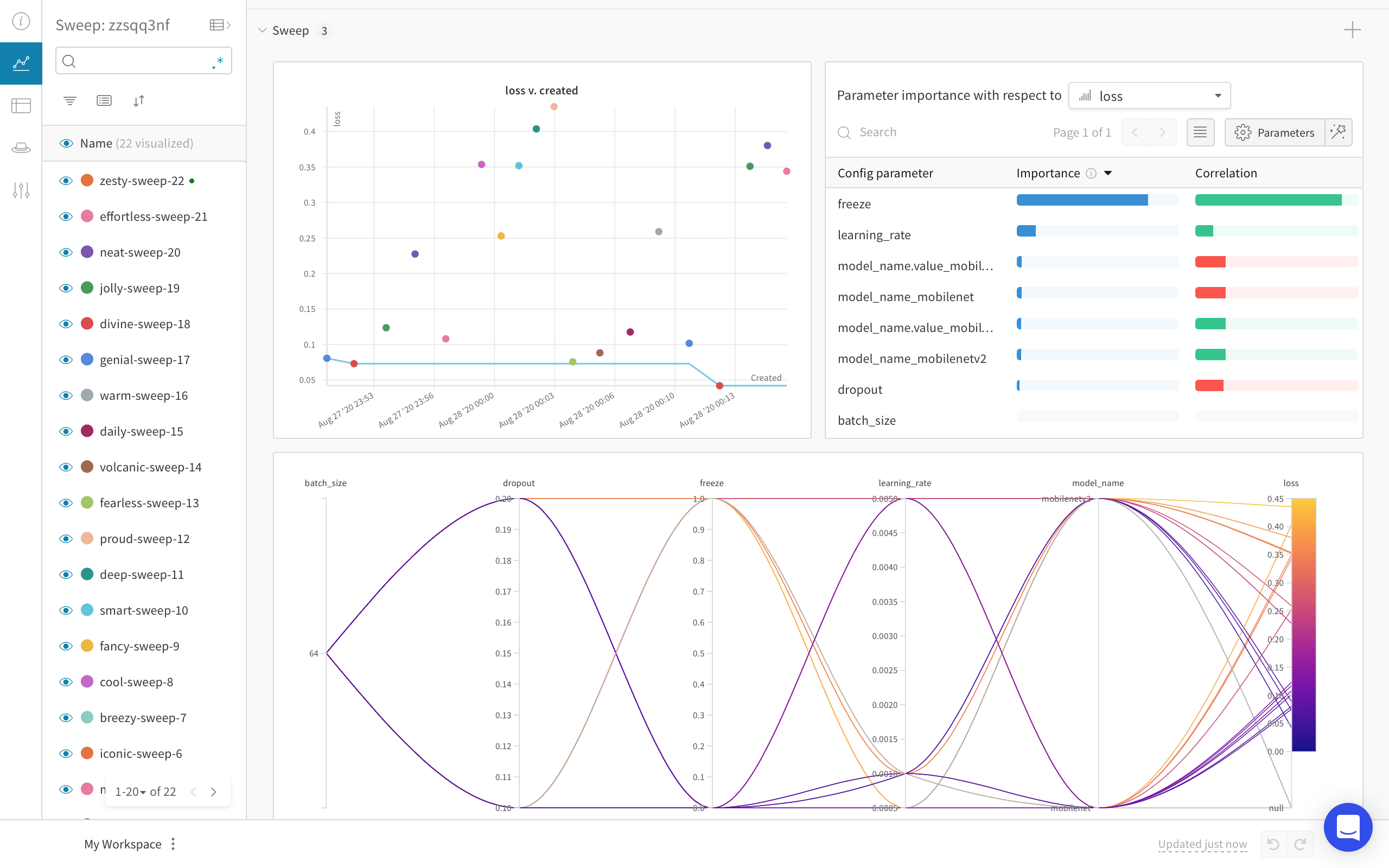
이번엔 Hyper parameter tuning을 편하게 할 수 있는 Weighs & Biases의 Sweep에 대해 알아봤습니다.
일일히 값을 변경하지 않고 지정해 놓으면 알아서 진행을 할테니..사용자는 좀 쉴……수 있겠죠..? (아닐 듯..)
그럼 포스팅을 마치겠습니다! 감사합니다!
wandb sweep 실행을 background 에서 하는 방법…?
nohup wandb agent {sweep_id} > nohup.out
이 다음은 뭐 하지…
