
Triton이라고 많이 부르는 Triton Inference Server는 다양한 딥 러닝 프레임워크(PyTorch, TensorFlow, ONNX 등)로 개발된 딥러닝 모델을 배포하고 추론(Inference)을 위한 고성능의 오픈 소스 추론 서버 솔루션으로 많은 곳에서 사용되고 있습니다.
그럼 Triton이 어떤 특징들이 있는지 알아보겠습니다!
유연한 모델 배포
TensorFlow, PyTorch, ONNX 등 다양한 딥 러닝 프레임워크로 개발된 모델을 지원하며, 이러한 모델들을 간편하게 배포할 수 있습니다.
고성능 추론
NVIDIA의 GPU를 활용하여 모델 추론을 가속화하고, 병렬 처리를 통해 높은 성능을 제공합니다. 이를 통해 대규모 추론 작업을 효율적으로 처리할 수 있습니다.
스케일링 및 병렬성
여러 모델의 병렬 추론을 지원하며, 여러 디바이스(GPU 또는 CPU)에서 동시에 모델을 실행하여 처리량을 최적화합니다.
다양한 프로토콜 지원
REST 및 gRPC 프로토콜을 통해 모델 추론 요청을 처리합니다. 이는 다양한 클라이언트 환경에서 모델을 사용할 수 있도록 합니다.
모델 관리 및 업데이트
모델 버전 관리를 통해 모델의 롤백, 비교, 추적 등을 지원하여 모델의 업데이트와 관리를 용이하게 합니다.
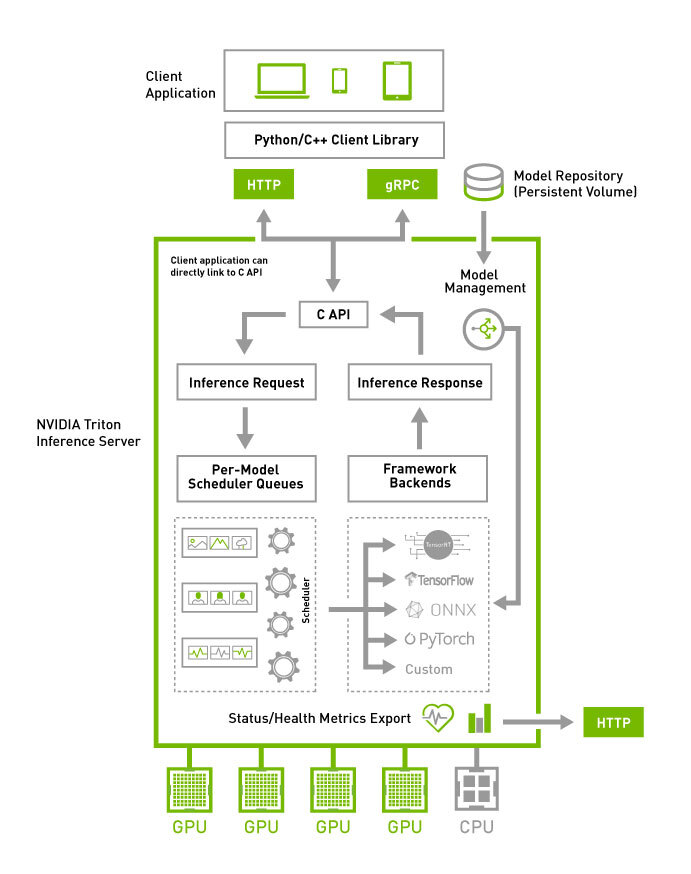
Triton Architecture(왜 캡션이…중앙으로 안갈까…)
위 사진은 Triton의 전체 구조를 모식도로 나타낸 것입니다.
처음 Triton을 접했을 때 ….? 라는 반응을 보인 부분이었습니다.
보통은 Flask, FastAPI, Django, 등등... 프레임워크를 쓰게 된다면...그게 곧 API인데요.
Triton의 경우 Inference Server가 따로 있고 Inference Server를 호출하는 Client가 따로 있습니다.(저만 몰랐던 부분일 것 같군요…)
예시를 적어보면 다음과 같습니다.
뭔가…더 복잡한 구조인 것 같지만 많은 자료들에서 일반적인 웹 프레임워크를 쓰는 것보다 훨씬 더 성능이 좋다고 하니 한번…. 간단 예제를 만들면서 추가적인 포스팅도 해봐야겠습니다…!
