
이번 포스팅에선 Weights & Biases 라는 Tool 을 소개드리려 합니다.
다음과 같은 특징을 강조하네요.
그럼 간단 사용법에 대해서 설명드리겠습니다.
wandb 패키지를 먼저 설치해줍니다.
pip install wandb
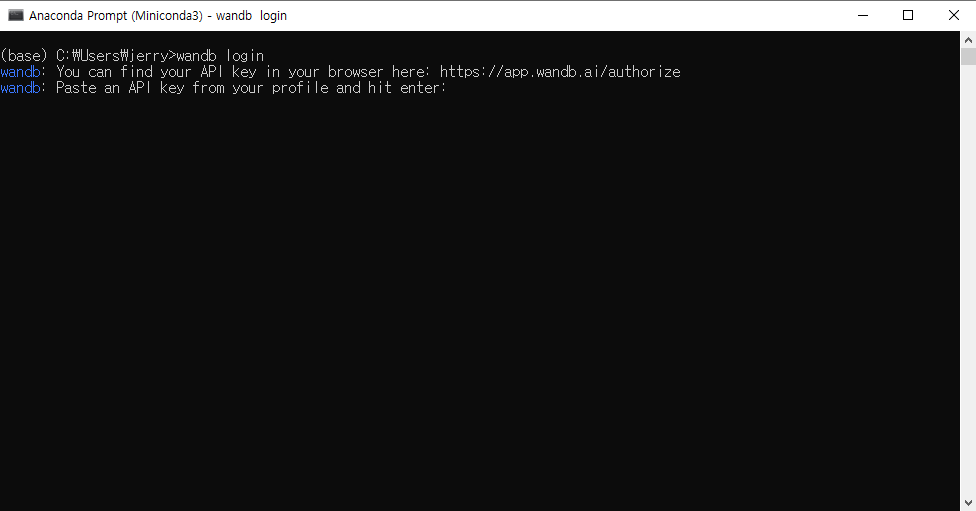
설치 후 Terminal (or 명령 프롬프트) 에 다음과 같이 입력합니다.
wandb login
그러면 아래와 같은 화면이 나오면서 웹 브라우저가 켜집니다.
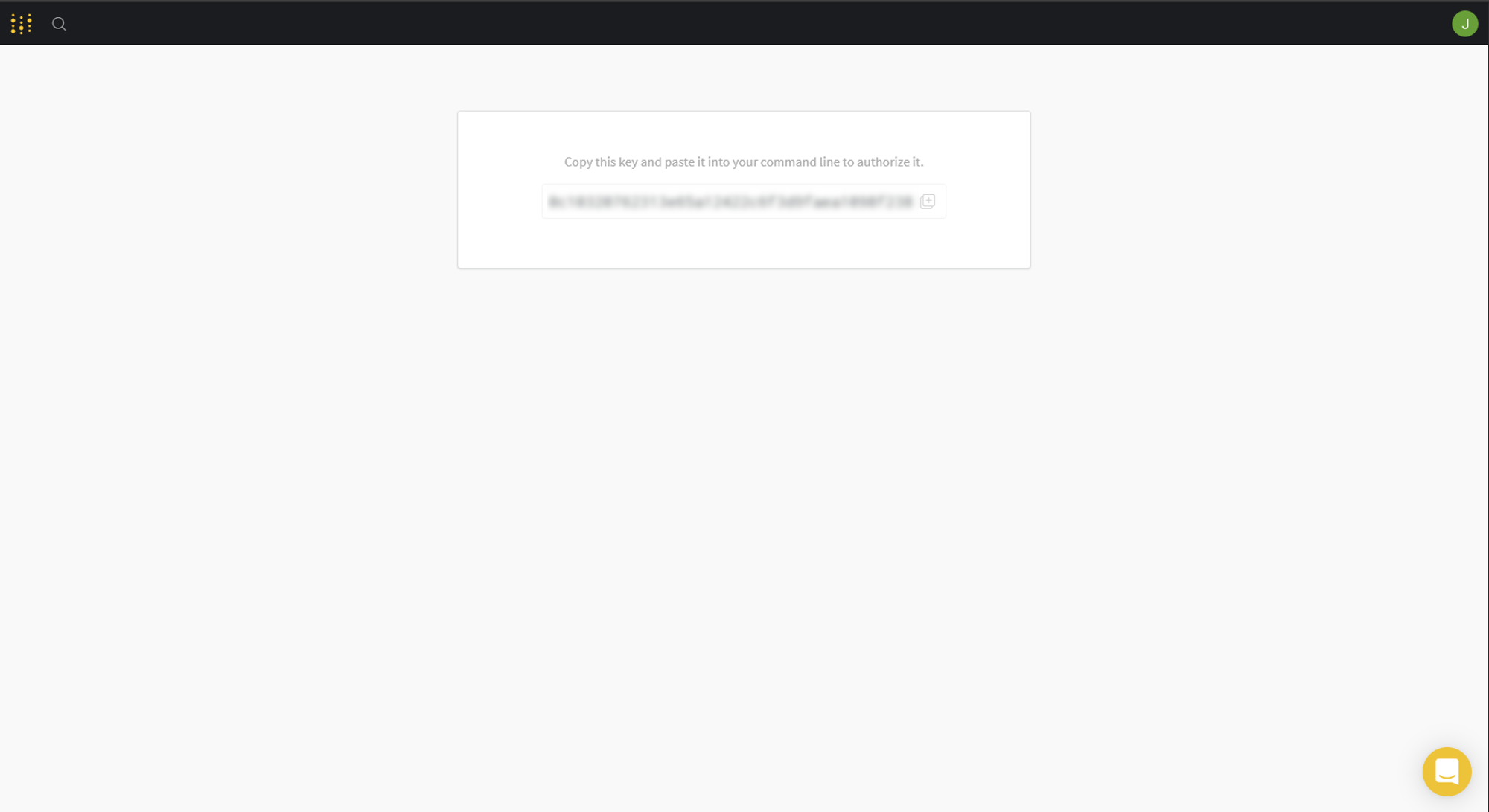
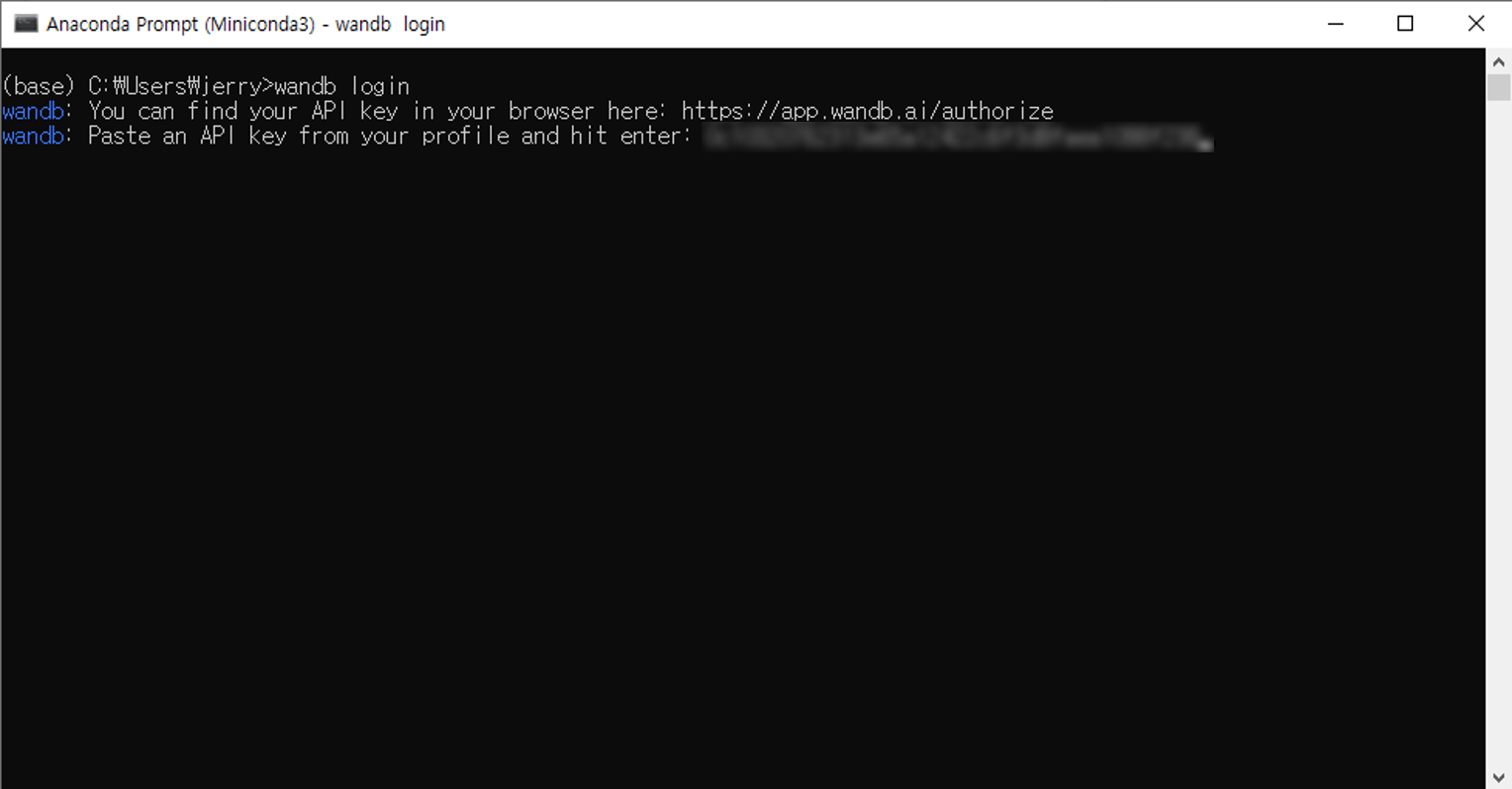
Browser 에서 API키를 복사해주해서 Terminal (or 명령 프롬프트) 에 붙여넣기합니다.
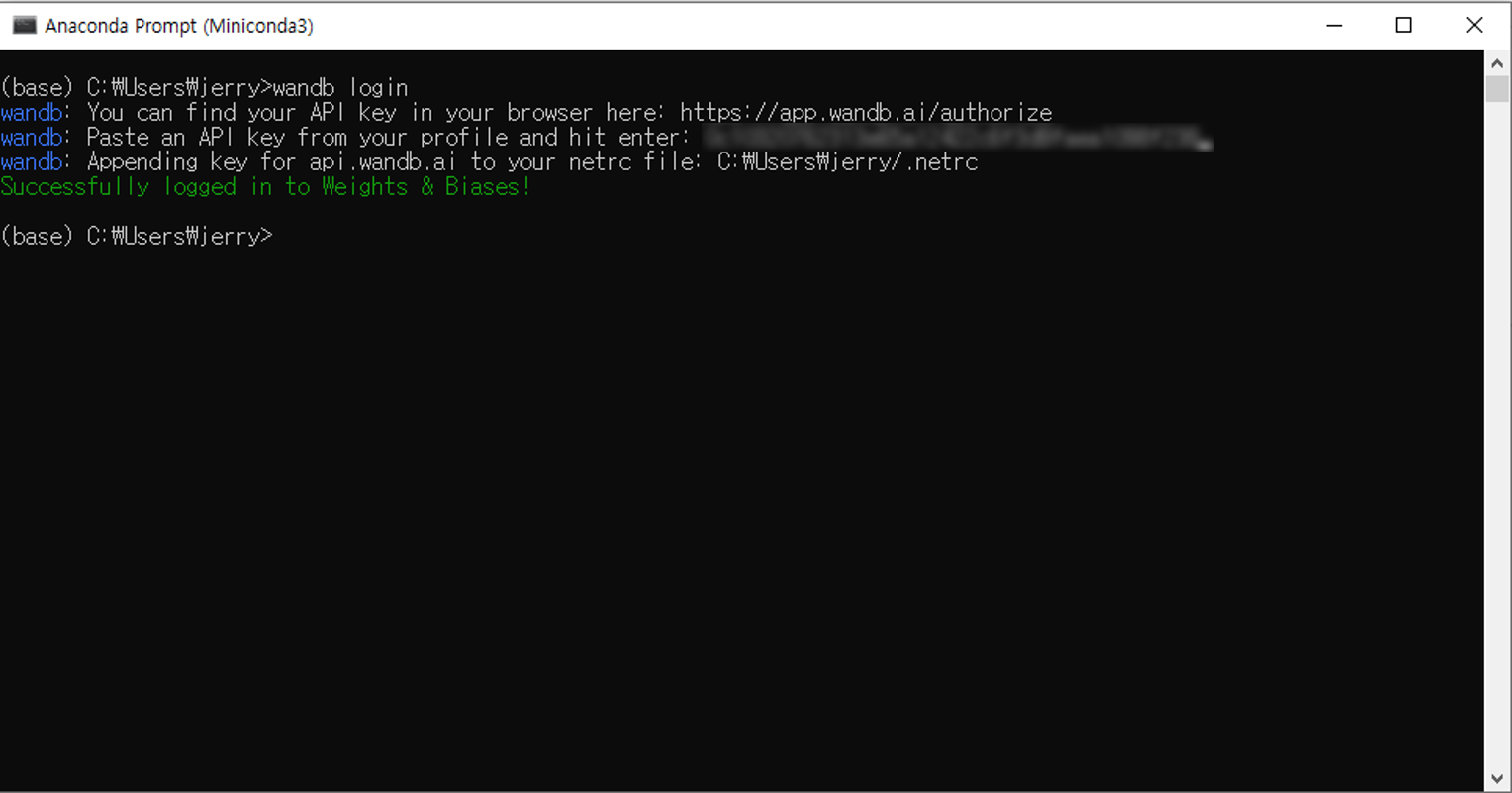
그럼 wandb 에 로그인 완료!
간단한 MLP를 이용한 MNIST Classification 문제입니다.
# wandb initialization
import wandb
wandb.init(project="test_project")
import os
import numpy as np
from matplotlib import pyplot as plt
import tensorflow as tf
from tensorflow.keras import models, layers, optimizers, losses, utils, datasets
# Import callback function
from wandb.keras import WandbCallback
print("Packge Loaded!")
# Data Loading
(train_x, train_y), (test_x, test_y) = datasets.mnist.load_data()
train_x, test_x = np.reshape(train_x/255., [-1, 784]), np.reshape(test_x/255., [-1, 784])
print("Train Data's Shape : ", train_x.shape, train_y.shape)
print("Test Data's Shape : ", test_x.shape, test_y.shape)
# Network Building
## Using Sequential
mlp = models.Sequential()
mlp.add(layers.Dense(256, activation='relu', input_shape=(784,)))
mlp.add(layers.Dense(128, activation='relu'))
mlp.add(layers.Dense(10, activation='softmax'))
print("Network Built!")
mlp.compile(optimizer=optimizers.Adam(), loss=losses.sparse_categorical_crossentropy, metrics=['accuracy'])
history = mlp.fit(train_x, train_y, epochs=10, batch_size=16,
validation_data=(test_x, test_y),
callbacks=[WandbCallback()]) # callbacks 에 Wandbcallback 추가
해당 코드를 실행시키고 W&B 에 접속을 하면 다음과 같은 화면이 나옵니다.
위에서 test_project 라는 프로젝트에 세팅을 했기 때문에 확인을 해봅니다.
하나의 프로젝트에서 한번 실행하면 뭔지 모를 조합의 Name으로 실행 상태를 보여줍니다.
저는 한번만 했기 때문에 lyric-dream-3 라는 이름으로 하나만 생겨있습니다.
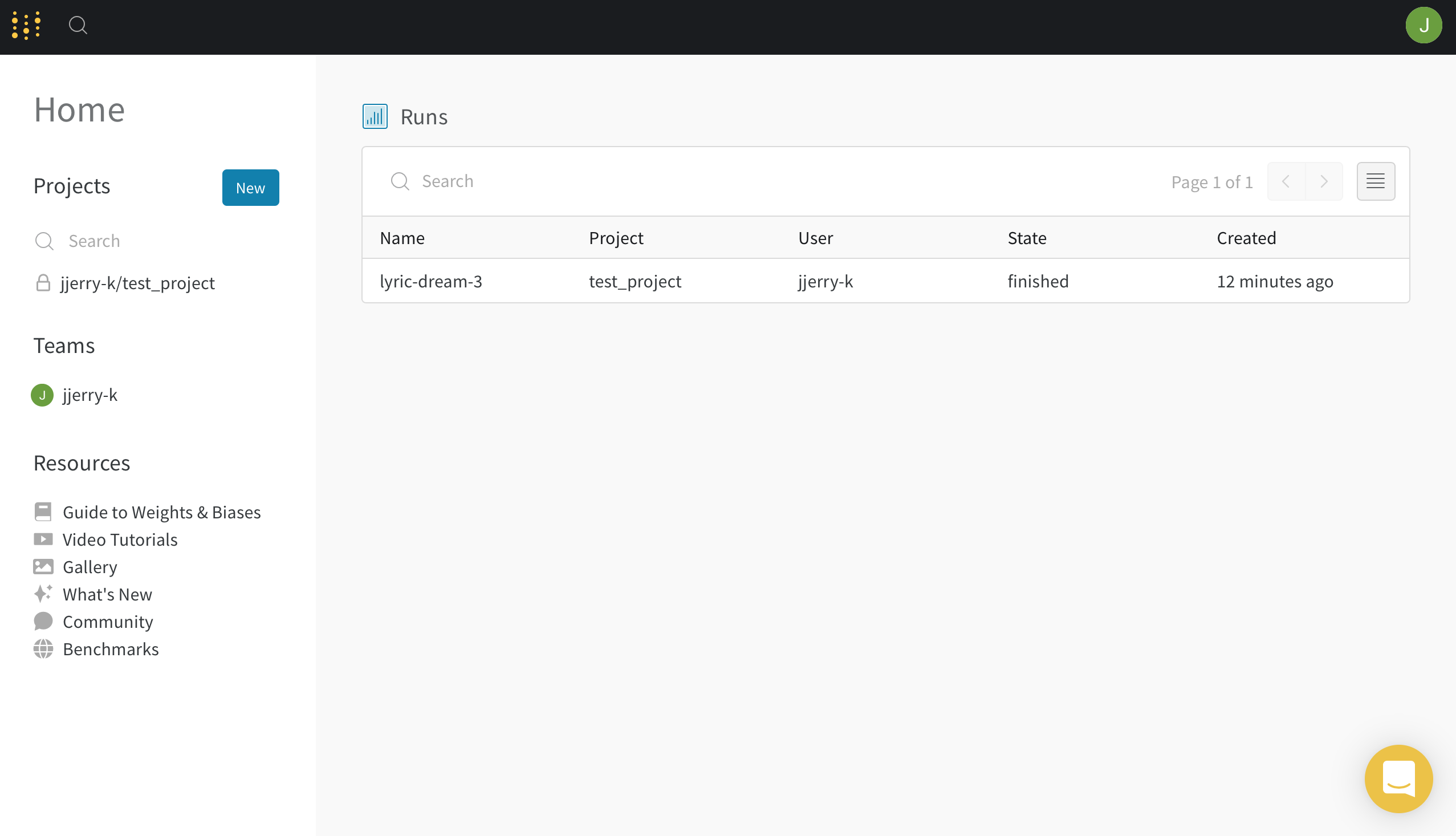
lyric-dream-3 같이 이름을 클릭해서 무엇을 볼 수 있는지 살펴보겠습니다.
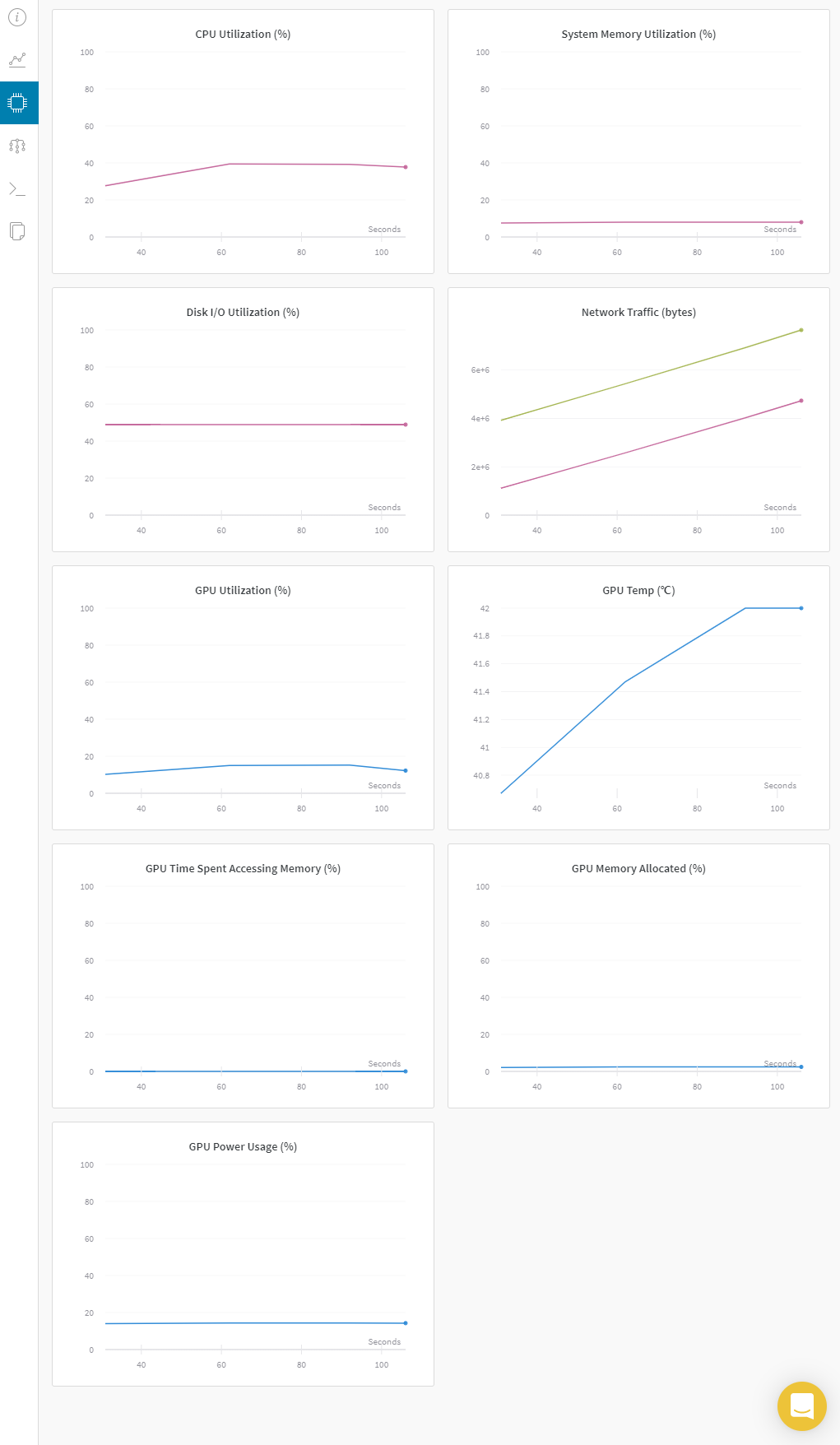
Chart 탭에선 loss, epoch, metric 등과 같은 학습 관련 지표를 볼 수 있는 CHARTS와 모델 학습에 사용된 시스템을 모니터링 할 수 있는 SYSTEM이 있습니다.
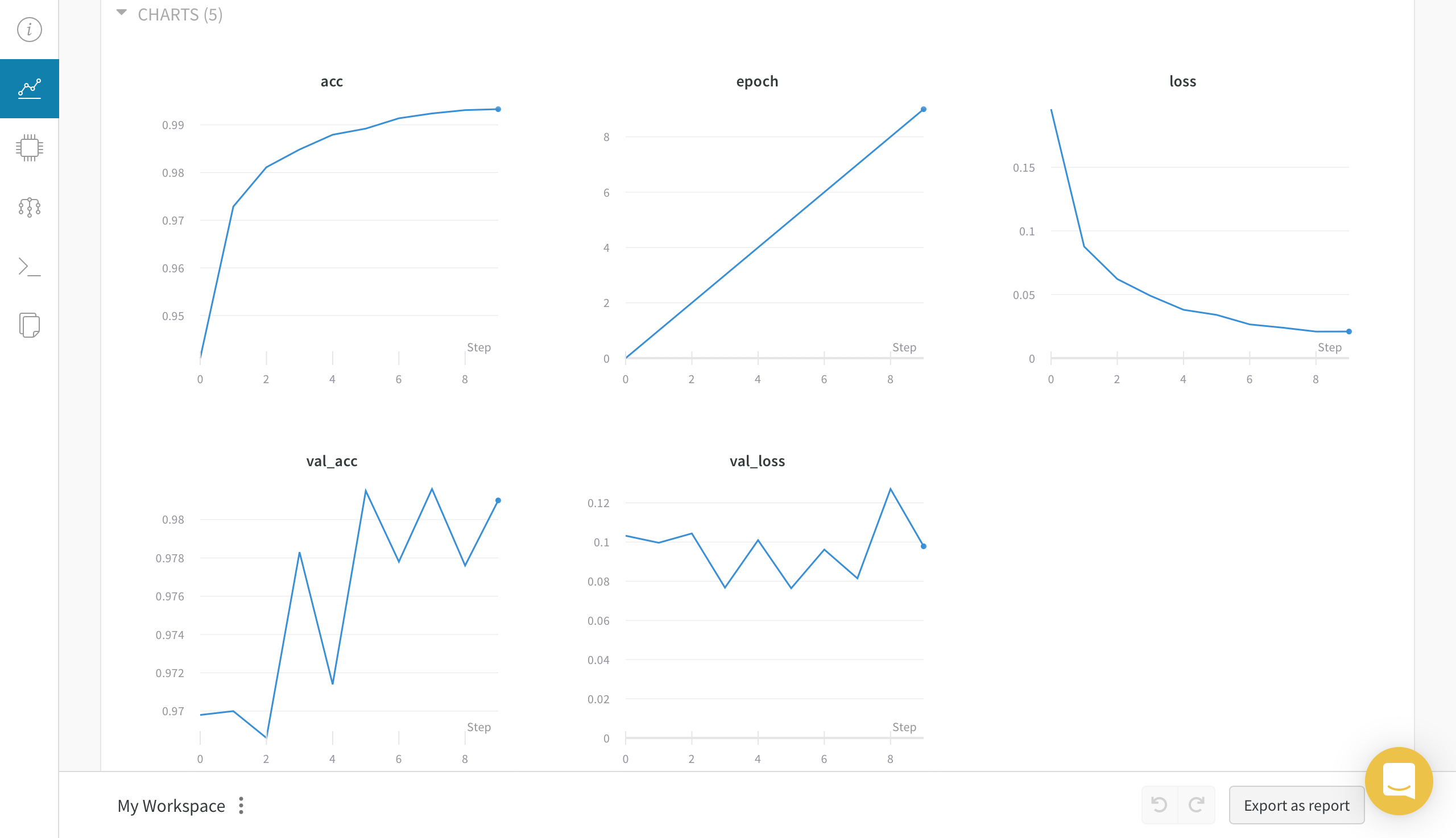
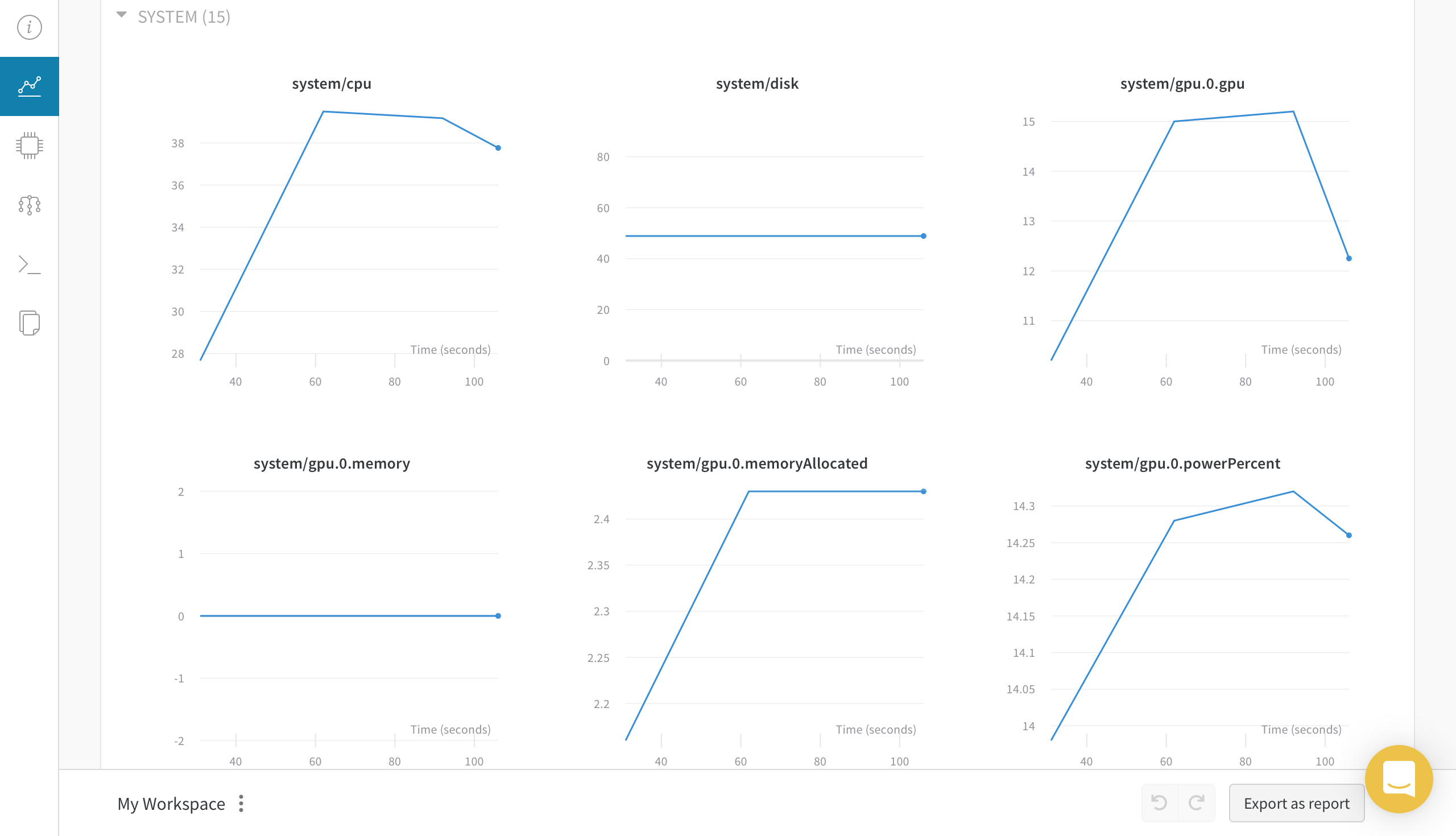
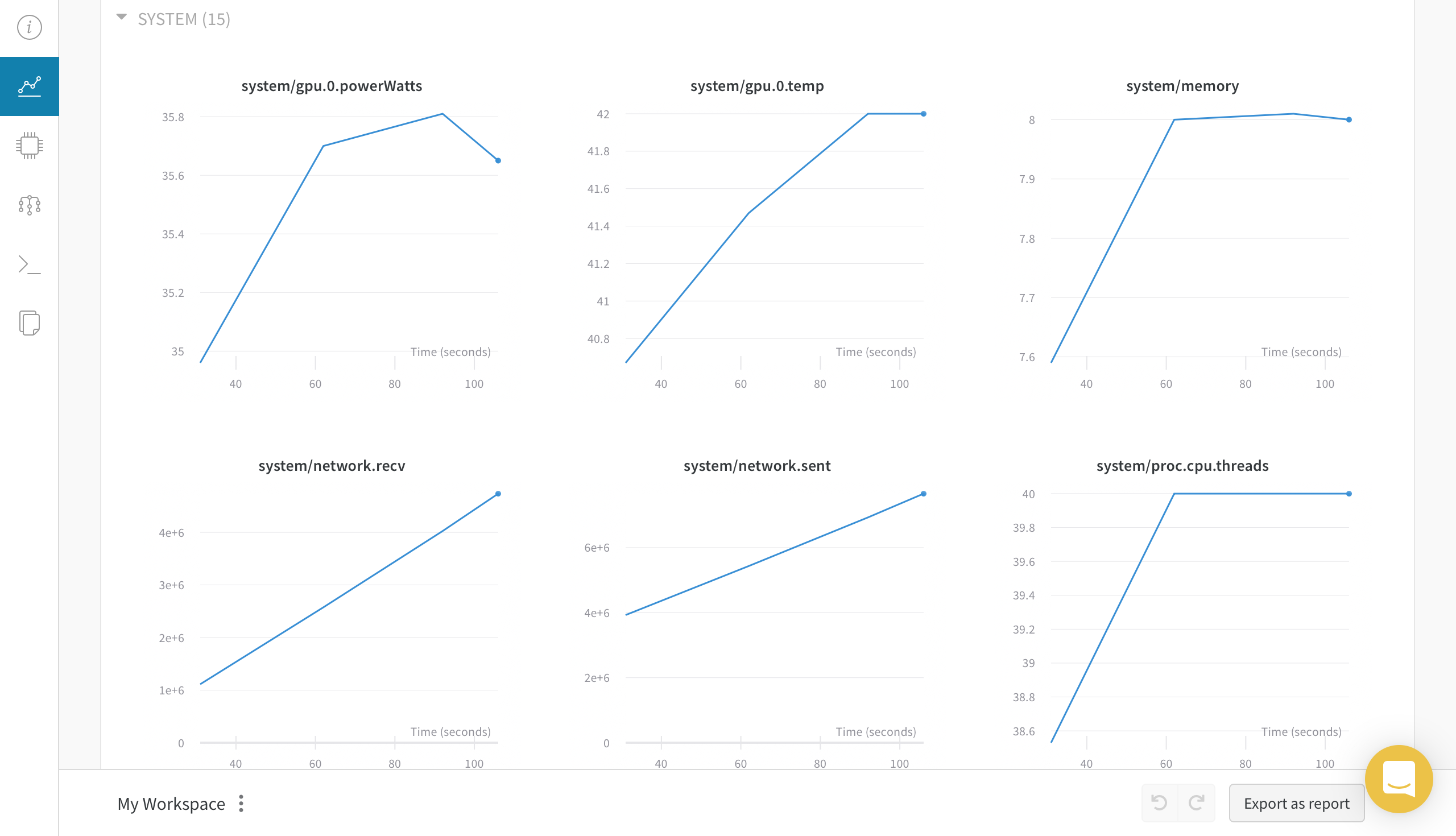
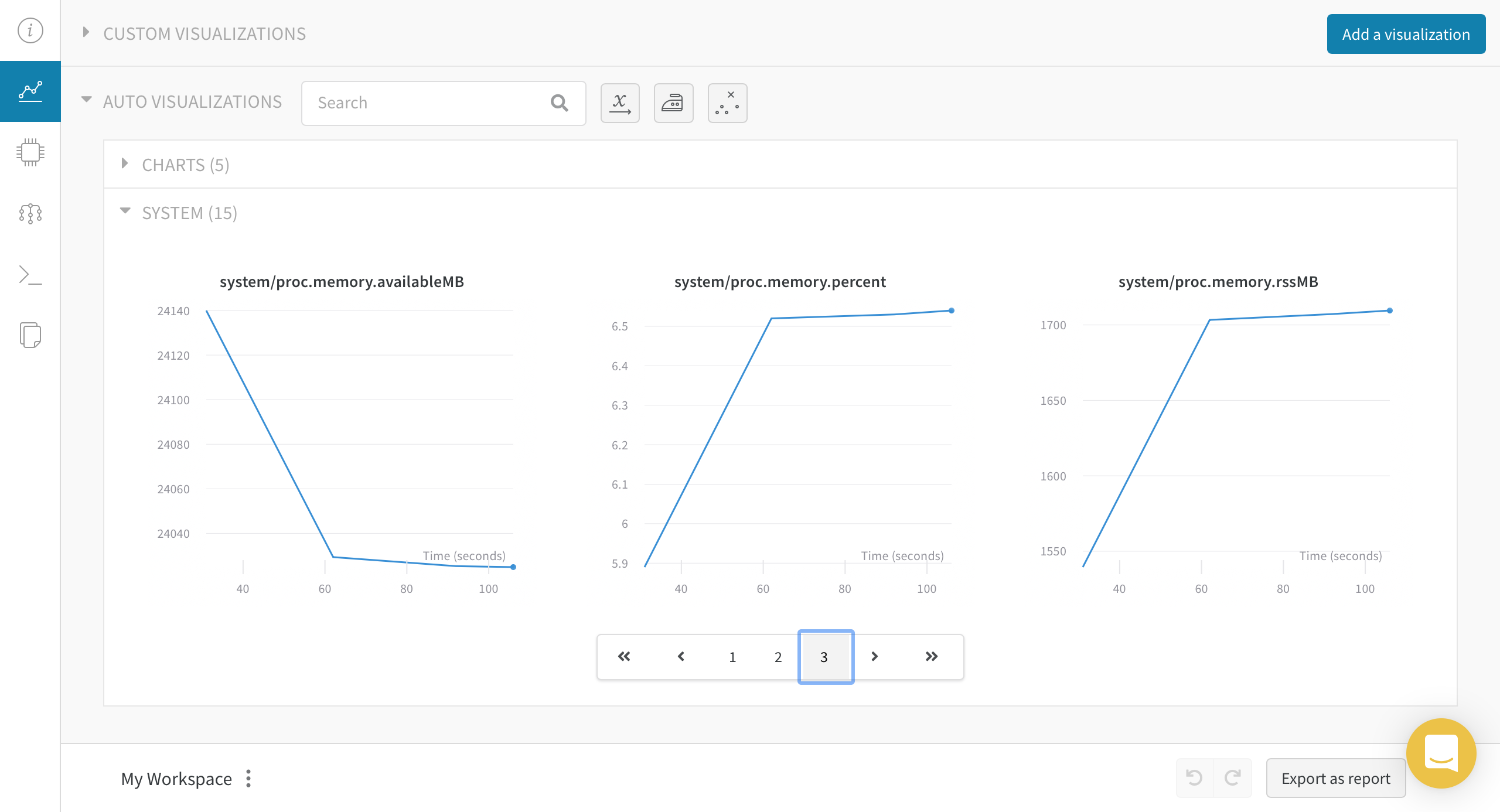
System 탭에서는 Chart 탭에서 SYSTEM 과 동일한 그래프를 보여주네요.
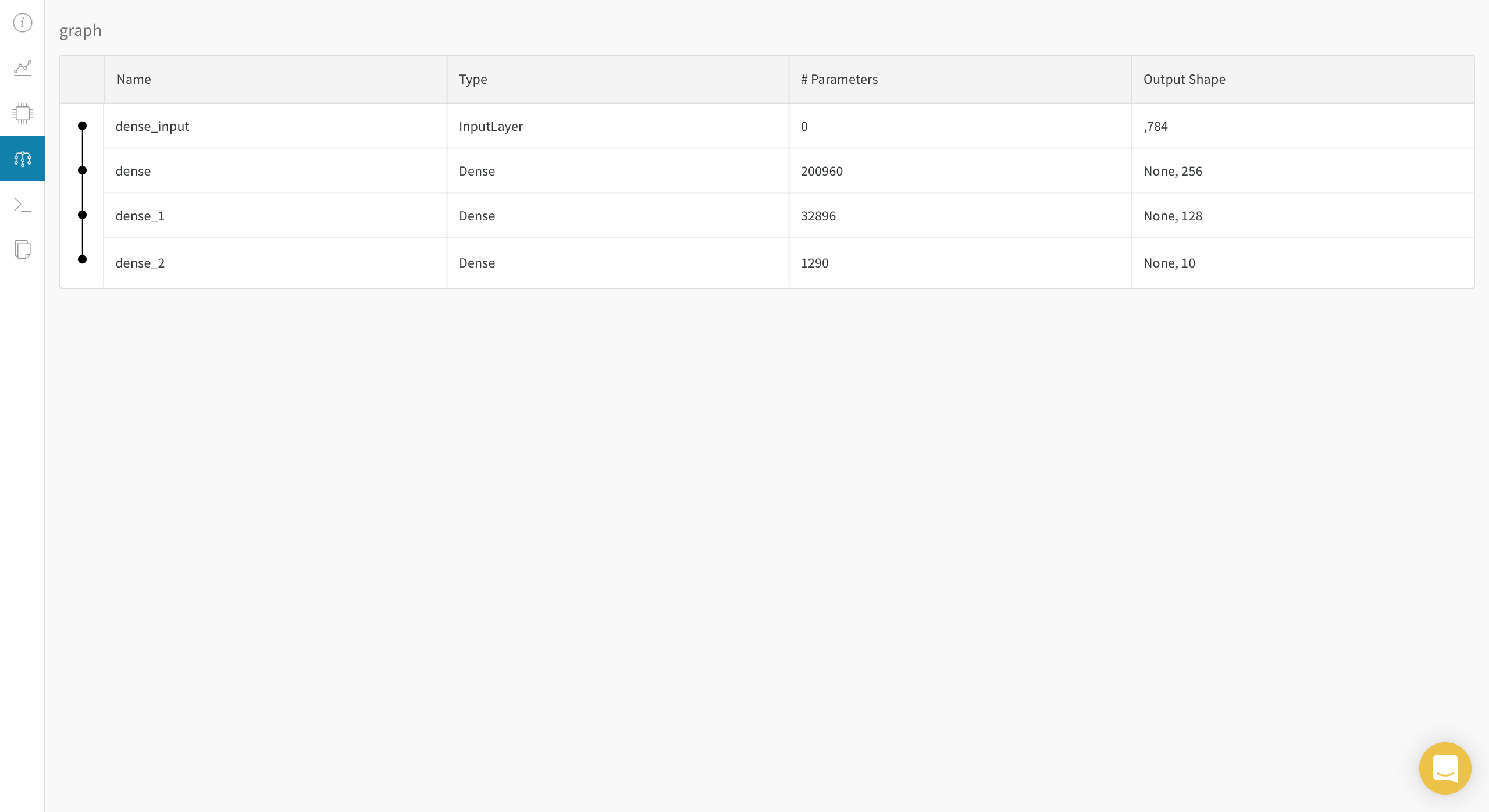
이름 그대로 학습하는 Model의 graph 구조를 볼 수 있습니다.
여기선 학습 로그들이 저장됩니다.
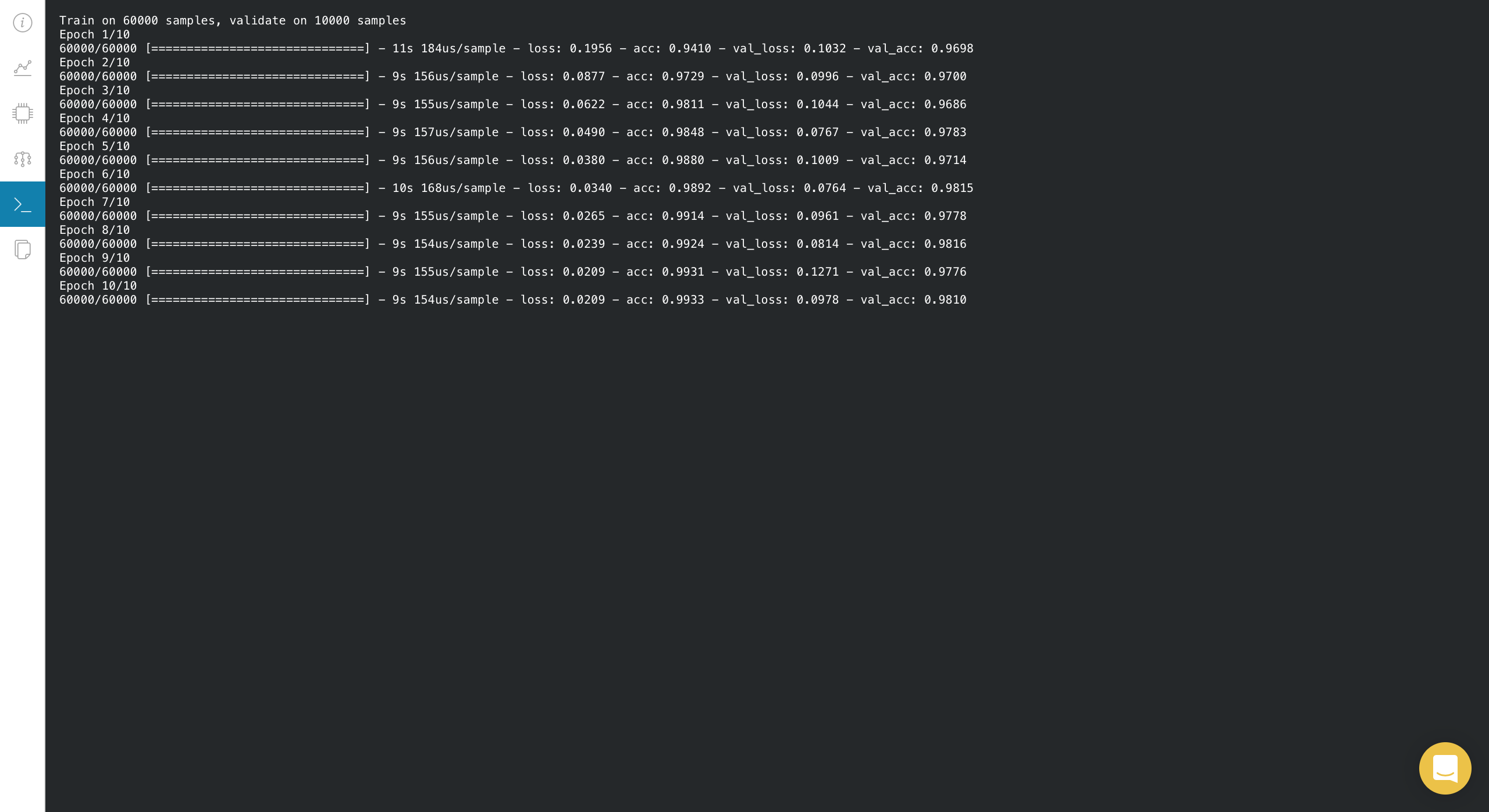
솔직히 보여주기만 해도 좋지만 저장도 해주면 좋겠죠.
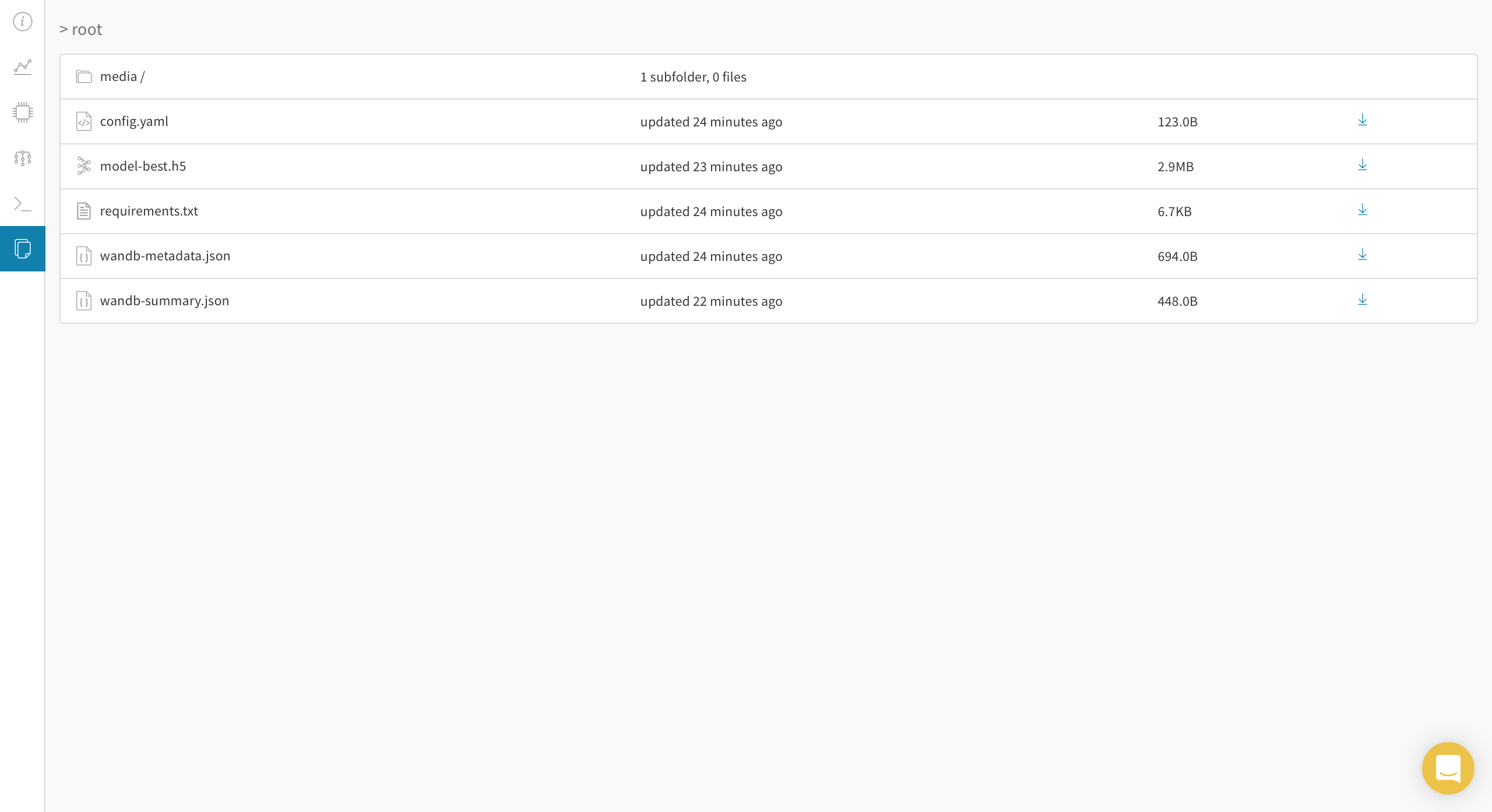
Files 탭에는 현재 모델을 돌릴때 사용된 정보, 가장 성능이 좋았을 epoch 의 model, 돌리는 환경에 설치된 package 리스트 등의 정보가 저장됩니다.
물론 다운로드 가능!
model-best.h5는 graph 정보도 저장되어 있기 때문에 다운로드 후 load해서 바로 Inference 가능합니다!
Weights & Biases 에 대해 정~~~말 간단히 알아봤습니다.
딱히 이런저런 기능은 추가를 하지 않고 기본적인 기능만 봤습니다.
추후에는 좀 더 다양한 기능과 프레임워크에 적용해보도록 하겠습니다.
# wandb initialization
import wandb
wandb.init(project="test_project")
# Importing Modules
import numpy as np
from matplotlib import pyplot as plt
import torch
from torch import nn, optim
import torch.nn.functional as F
from torchvision import utils, datasets, transforms
# Loading Data
# MNIST dataset
mnist_train = datasets.MNIST(root='./',
train=True,
transform=transforms.ToTensor(),
download=True)
print("Downloading Train Data Done ! ")
mnist_test = datasets.MNIST(root='./',
train=False,
transform=transforms.ToTensor(),
download=True)
print("Downloading Test Data Done ! ")
# Defining Model
# our model
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(784, 256)
self.linear2 = nn.Linear(256, 10)
def forward(self, X):
X = F.relu((self.linear1(X)))
X = self.linear2(X)
return X
model = Model()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Logging model, Gradient, parameters on dashboard
wandb.watch(model)
# Training Phase
batch_size = 100
data_iter = torch.utils.data.DataLoader(mnist_train, batch_size=100, shuffle=True, num_workers=1)
print("Iteration maker Done !")
# Training loop
for epoch in range(10):
avg_loss = 0
total_batch = len(mnist_train) // batch_size
for i, (batch_img, batch_lab) in enumerate(data_iter):
X = batch_img.view(-1, 28*28)
Y = batch_lab
y_pred = model.forward(X)
loss = criterion(y_pred, Y)
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss
if (i+1)%100 == 0 :
print("Epoch : ", epoch+1, "Iteration : ", i+1, " Loss : ", avg_loss.data.numpy()/(i+1))
# Logging metrics
wandb.log({'epoch': epoch+1, "loss": avg_loss.data.numpy()/(i+1)})
print("Epoch : ", epoch+1, " Loss : ", avg_loss.data.numpy()/total_batch)
print("Training Done !")
# Save final model
torch.save(model.state_dict(), "model.h5")
wandb.save('model.h5')
# Evaluation
test_img = mnist_test.data.view(-1, 28*28).type(torch.FloatTensor)
test_lab = mnist_test.targets
outputs = model.forward(test_img)
pred_val, pred_idx = torch.max(outputs.data, 1)
correct = (pred_idx == test_lab).sum()
print('Accuracy : ', correct.data.numpy()/len(test_img)*100)
# Testing
r = np.random.randint(0, len(mnist_test)-1)
X_single_data = mnist_test.data[r:r + 1].view(-1,28*28).float()
Y_single_data = mnist_test.targets[r:r + 1]
single_prediction = model(X_single_data)
plt.imshow(X_single_data.data.view(28,28).numpy(), cmap='gray')
print('Label : ', Y_single_data.data.numpy()[0])
print('Prediction : ', torch.max(single_prediction.data, 1)[1].numpy()[0])
